关于抑郁症
Here's something encrypted, password is required to continue reading.
作者:来源不详
在时间上,纽约走在加州前面三个小时,
但加州并没有变慢。
有人22岁就毕业了,
但等了五年才找到好工作!
有人25岁就当上了CEO,
却在50岁去世了。
也有人直到50岁才当上CEO,
最后活到90岁。
有人依然单身,
而别人却早已结婚。
奥巴马55岁退任总统,
而川普却是70岁才开始当。
世上每个人都有自己的发展时区。
身边有些人看似走在你前面,
也有人看似走在你后面。
但其实每个人在自己的时区有自己的步程。
不用嫉妒或嘲笑他们。
他们都在自己的时区,你在你的!
所以,别放松。
你没有落后,
你没有领先。
在命运为你安排的属于你自己的时区里,一切都非常准时。
好,别忘了危机与奋斗
难,别忘了梦想与坚持
忙,别忘了读书与锻炼
人生,就是一场长跑
New York is 3 hours ahead of California,
but it does not make California slow.
Someone graduated at the age of 22,
but waited 5 years before securing a good job!
Someone became a CEO at 25,
and died at 50.
While another became a CEO at 50,
and lived to 90 years.
Someone is still single,
while someone else got married.
Obama retires at 55,
but Trump starts at 70.
Absolutely everyone in this world works based on their Time Zone.
People around you might seem to go ahead of you,
some might seem to be behind you.
But everyone is running their own RACE, in their own TIME.
Don’t envy them or mock them.
They are in their TIME ZONE, and you are in yours!
So, Never Give up
You’re not LATE.
You’re not EARLY.
You are very much ON TIME, and in your TIME ZONE Destiny set up for you.
Well, Don’t forget the crisis and the struggle.
Hard. Don’t forget the dream and the persistence.
Busy, Don’t forget to read and exercise
Life is a long run
作者:罗伯特·弗罗斯特
黄色的树林里分出两条路,
可惜我不能同时去涉足,
我在那路口久久伫立,
我向着一条路极目望去,
直到它消失在丛林深处。
但我却选了另外一条路,
它荒草萋萋,十分幽寂,
显得更诱人、更美丽;
虽然在这两条小路上,
都很少留下旅人的足迹;
虽然那天清晨落叶满地,
两条路都未经脚印污染。
呵,留下一条路等改日再见!
但我知道路径延绵无尽头,
恐怕我难以再回返。
也许多少年后在某个地方,
我将轻声叹息把往事回顾:
一片树林里分出两条路,
而我选了人迹更少的一条,
从此决定了我一生的道路。
Two roads diverged in a yellow wood,
And sorry I could not travel both
And be one traveler, long I stood
And looked down one as far as I could
To where it bent in the undergrowth;
Then took the other, as just as fair,
And having perhaps the better claim,
Because it was grassy and wanted wear;
Though as for that the passing there
Had worn them really about the same,
And both that morning equally lay
In leaves no step had trodden black.
Oh, I kept the first for another day!
Yet knowing how way leads on to way,
I doubted if I should ever come back.
I shall be telling this with a sigh
Somewhere ages and ages hence:
Two roads diverged in a wood,and I—
I took the one less traveled by,
And that has made all the difference.
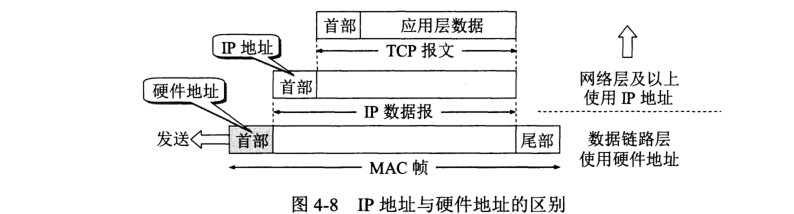
应用层许多协议都是基于客户服务器方式。即便是 P2P 实质上也是一种特殊的客户服务器方式,客户 (clinet) 和服务器 (server) 都是指通信中涉及的两个应用进程。
域名系统 DNS 能把互联网上的主机名字转换为 IP 地址。互联网采用层次树状结构的命名方法,并使用分布式的域名系统 DNS。DNS 使大多数名字都在本地进行解析 (resolve),仅少量解析需要在互联网上进行通信。
域名到 IP 地址的解析是由分布在互联网上的许多域名服务器程序共同完成的,人们也常讲运行域名服务器程序的机器称为域名服务器。
域名解析的请求以 UDP 用户数据报的方式进行传输。具体传输路径待后续探讨。
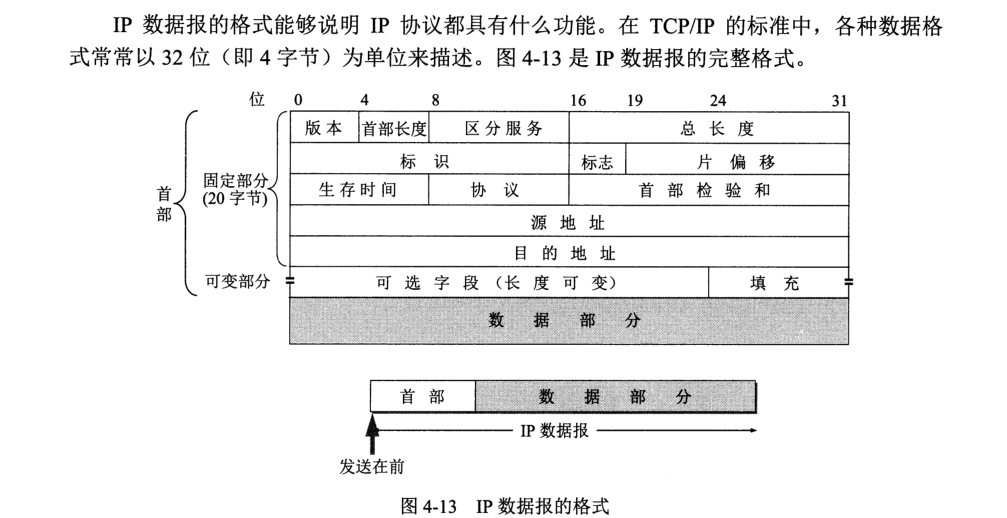
互联网采用层次树状结构进行命名,任何一个连接在互联网上的主机或路由器,都有一个唯一的层次结构的名字,即域名 (domain name)。域还可以划分为子域,这样就形成了顶级域、二级域、三级域等等。每个域名由标号 (label) 序列组成,各标号间用点隔开,

顶级域名分为四大类:
二级域名划分为类别域名和行政区域名两大类。
一般采用域名树来表示互联网的域名系统,其中根节点无名,如图:
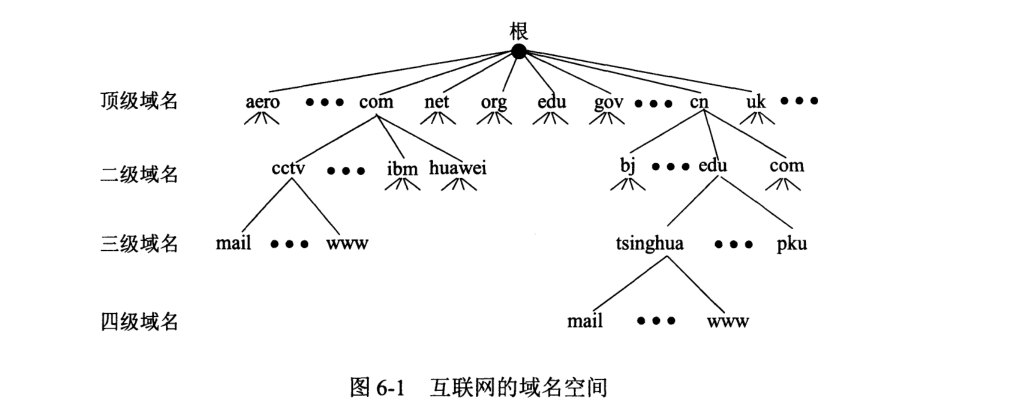
一个服务器管辖的范围叫做区 (zone),一个区中所有节点必须联通。每一个区设置相应的权限域名服务器 (authoritative name server),用于保存该区主机域名到 IP 的映射。
按照所起作用,可将域名服务器划分为四种不同类型:
主机向本地服务器查询一般采用递归查询,即逐步深入。而本地服务器向根域名服务器查询采用迭代查询,即遍历询问。
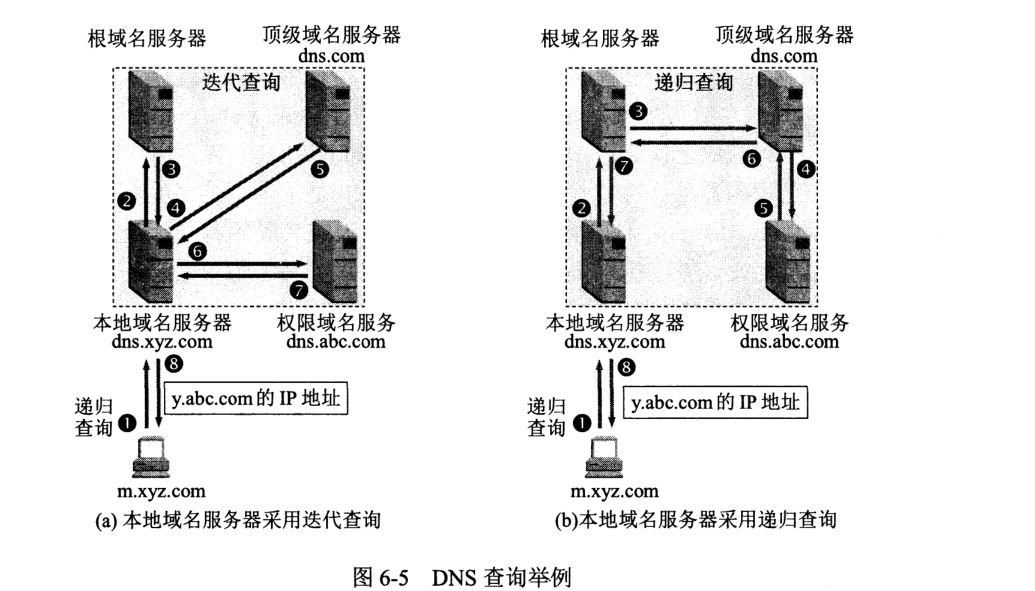
为提高可靠性,DNS 域名服务器还将数据复制到几个域名服务器保存,其中一个为主域名服务器 (master name server),其余为辅助域名服务器 (secondary name sever)。
为提高效率,域名服务器广泛使用高速缓存,存放最近查询过的域名以及从何处获得域名映射信息的记录。域名服务器为每项内容设置计时器并处理超时项。
文件传送协议 FTP (File Transfer Protocol) 提供交互式访问,允许客户指明文件类型与格式,并允许文件具有存取权限。屏蔽系统细节,适合于在异构网络中任意计算机间传送文件。
基于 TCP 的 FTP 和基于 UDP 的 TFTP 是文件共享协议的一大类,即复制整个文件,欲修改文件,只能修改副本,然后将整个副本传回。
另一大类是联机访问 (on-line access)。由操作系统提供对远地文件进行访问的服务,如同对本地文件访问一样。操作系统提供透明存取。透明存取优点为更改远地文件时无需作过多改动。属于该协议的有网络文件系统 NFS (Network File System)。
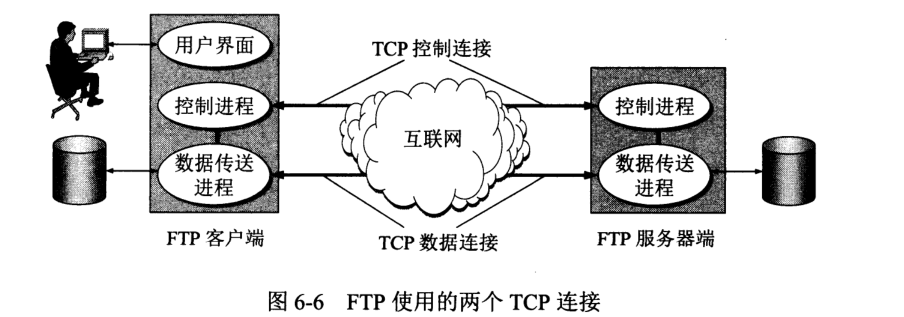
采用客户服务器方式。FTP 服务器进程由两大部分组成:一个负责接收请求的主进程和若干个负责处理单个请求的从属进程。工作步骤如下:
主进程即负责控制连接,从属进程即负责数据连接。FTP 控制信息是带外 (out of band) 传送的。
NFS 允许应用进程打开一个远地文件并从某一特定位置开始读写数据,在网络上传送的仅是少量修改数据。
两个优点:
主要特点:
发送一方在规定时间内收不到确认就需重发数据 PDU。 TFTP 熟知端口号码为 69。
TELNET 能将用户击键传到远地主机,也能将远地主机输出通过 TCP 连接返回用户屏幕。又称终端仿真协议。
为了适应不同操作系统的差异,TELNET 定义了数据和命令应怎样通过互联网,这些定义就是所谓的网络虚拟终端 NVT (Network Virtual Terminal)。
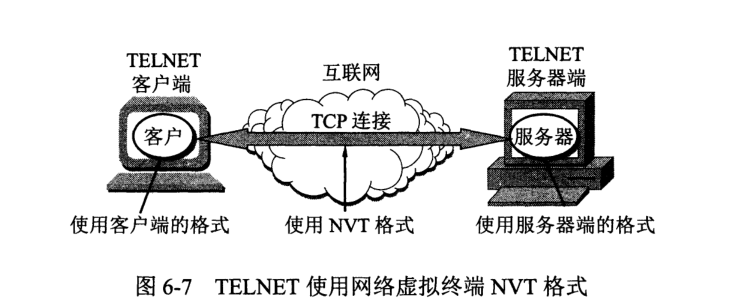
NVT 的格式定义很简单。所有通信都使用 8 位一个字节。运转时,采用 7 位 ASCII 码传输数据,最高位为 1 时用作控制命令。定义了两字符的 CR-LF 作为标准的行结束控制符。
万维网是一个大规模的、联机式的信息储藏所。能方便地从一个站点访问(或称链接到)另外一个站点。万维网是一个分布式的超媒体 (hypermedia) 系统,是超文本 (hypertext) 系统的扩充。超文本是指包含指向其它文档的链接的文本。超文本是万维网的基础。
万维网以客户服务器的方式工作。客户发出请求,服务器返回客户所需的万维网文档。万维网必须解决如下几个问题:
常用协议 http,其次是 ftp。<主机>指出万维网文档的位置,<端口>和<路径>有时可以省略。
HTTP 默认端口号 80,通常可省略。若再省略路径,则连接到主页 (home page)。

从层次角度看,HTTP 是面向事务的 (transaction-oriented) 应用层协议,可以传输任何可从互联网上得到的信息,如文本、超文本、声音和图像等。
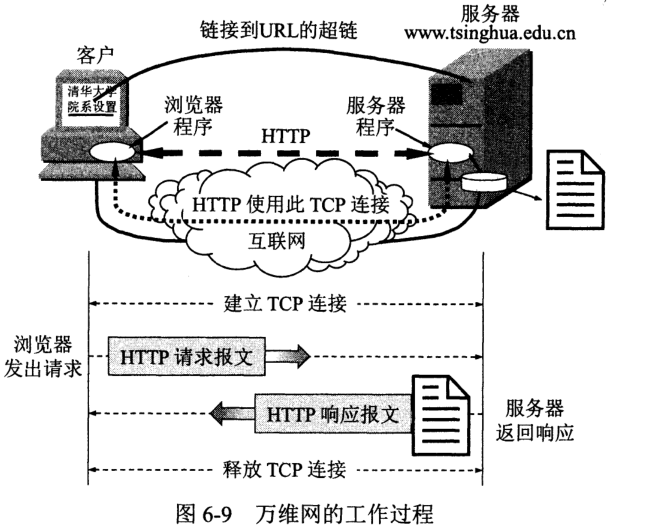
每个万维网网点都有一个服务器进程,不断监听 TCP 端口 80,以便发现是否有连接建立请求。一旦监听到连接建立请求并建立 TCP 连接后,浏览器就发出浏览某个页面的请求,服务器就返回页面作为响应。这种交互过程遵循的格式和规则,就是 HTTP。
HTTP 报文通常使用 TCP 的连接传送,但 HTTP 本身是无连接的。
HTTP 协议是无状态的 (stateless)。每次访问时服务器响应都相同,并不记录曾经的访问。
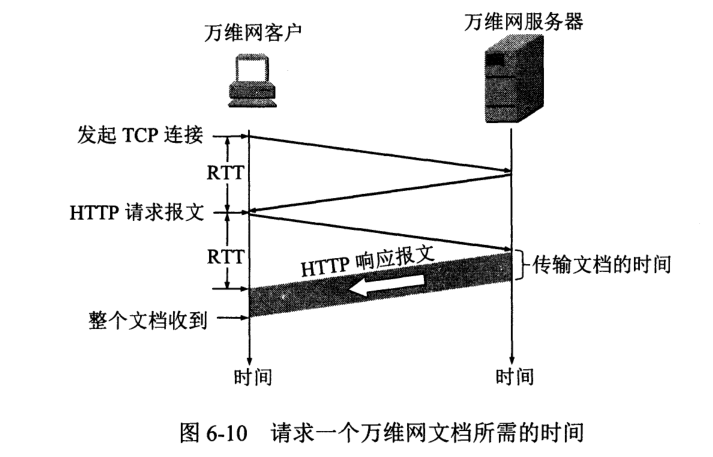
如图所示,请求一个 Web 文档所需时间是传输时间加上两倍往返时间 RTT。
HTTP/1.0 每次请求都有两倍 RTT 开销,加上每建立一次连接都需要分配缓存和变量,开销很大,这种非持续连接会使 Web 服务器负担很重。
HTTP/1.1 协议使用了持续连接,响应后仍在一段时间内保持该条连接,响应同一个服务器的请求。该协议有两种工作方式,非流水线方式 (without pipelining) 和流水线方式 (with pipelining)。
非流水线特点是,客户收到前一个响应后才能发出下一个请求,节省了建立连接所需一个 RTT 时间。
流水线方式特点是,客户收到响应前就可发送下一个请求,服务器可连续响应,访问所有对象只需一个 RTT 时间,提高了效率。
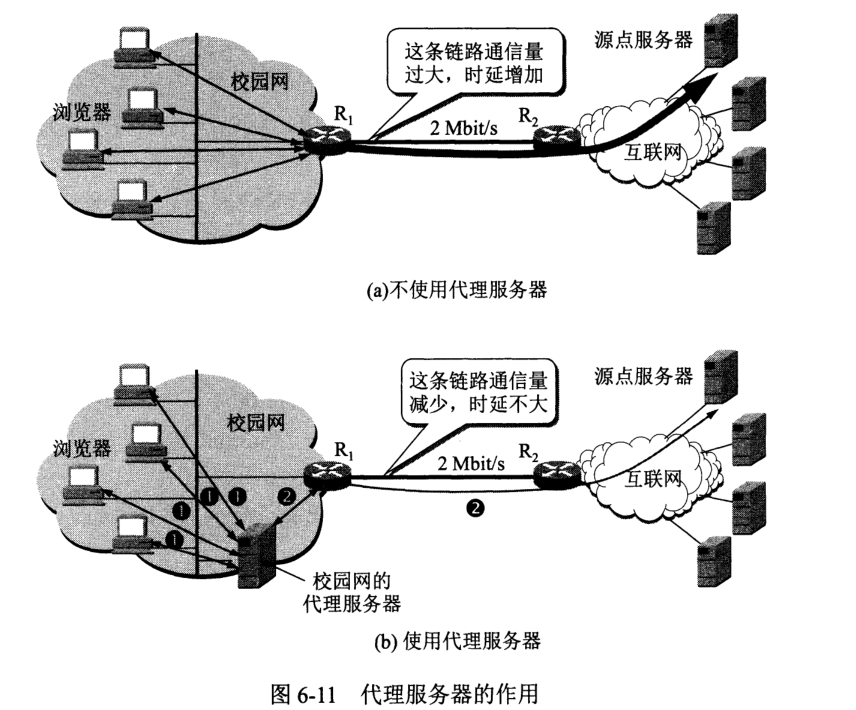
代理服务器 (proxy server) 又称万维网高速缓存 (Web cache)。将最近的一些请求和响应暂存于本地磁盘,新请求到达先经代理服务器查询,查询不到则作为客户发送请求。
HTTP 有两类报文:请求报文和响应报文。
HTTP 是面向文本的 (text-oriented),因此报文每个字段都是一些 ASCII 码。
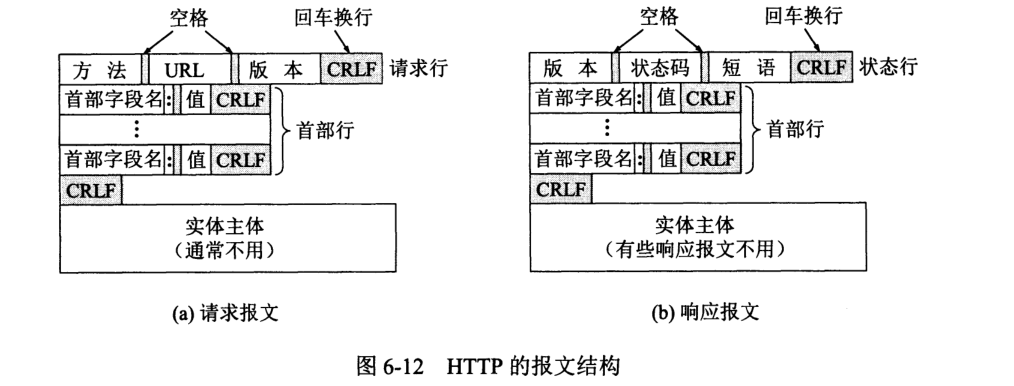
开始行:请求报文称请求行 (Request-Line),响应报文称状态行 (Status-Line)。最后 CR 和 LF 分别代表回车和换行。
超文本标记语言 HTML 是一种制作 Web 页面的标准语言。其中插入链接的终端可以是其它网站页面,称远程链接;亦可为本地计算机的某一个文件或文件某处,称本地连接。
XML (Extensible Markup Language) 是可扩展标记语言,设计宗旨是传输数据。
XHTML (Extensible HTML) 是可扩展超文本标记语言,是更严格的 HTML 版本,并将逐渐取代 HTML。
CSS 是层叠样式表。HTML 负责结构化内容,CSS 负责格式化结构化的内容。
以上都是静态文档 (static document),创建完即不会改变。缺点是不够灵活,但 HTML 可以由不懂程序设计的人员创建,优点是简单。
动态文档 (dynamic document) 是指文档内容是在浏览器访问万维网服务器时才由应用程序动态创建的。动态文档的开发是编写用于生成文档的应用程序,因此开发难度更大。实现动态文档需要对 Web 服务器的功能进行扩充:
通用网关接口 CGI (Common Gateway Interface) 是一种标准,定义动态文档该如何创建,输入数据该如何提供给应用程序,输出结果应如何使用。 CGI 的正式名是 CGI 脚本 (script),又称 cgi-bin 脚本,因为在许多 Web 服务器上,为便于找到 CGI 程序,就放在 /cgi-bin 目录下。
6.4.4.3 活动 Web 文档
有两种技术可用于浏览器屏幕显示的连续更新:
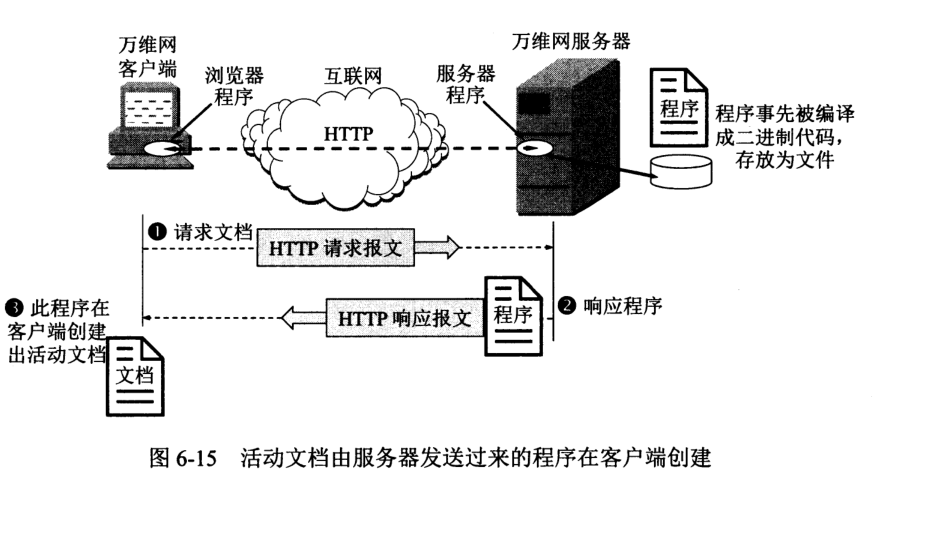
Java 技术是用于创建和运行活动文档的技术,是活动文档技术的一部分。
工具是搜索引擎 (search engine),分两大类,全文检索搜索引擎和分类目录搜索引擎。
全文搜索引擎通过搜索软件到互联网上各网站收集信息,建立一个在线索引数据库供用户查询,这种索引数据库必须及时更新以剔除过时信息。全文检索可以检索出大量信息,但缺点是结果不够准确。
分类搜索引擎并不采集任何信息,而是用个网站向搜索引擎提交网站信息时填写的关键词和网站描述等信息,经审核后输入到分类目录数据库中,供用户查询。查询时无需使用关键词,只需按照分类,因而查询准确性较好。
目前出现了垂直搜索引擎,在关键词检索基础上限制搜索领域,返回结果更倾向于信息、消息、条目等。
还有元搜索引擎,将用户提交的检索发送到多个独立的搜索引擎上,处理结果并返回,重在提高搜索速度、智能化搜索结果、个性化搜索。查全率和准确率都较高。
Google 搜索软件同时进行许多运算,核心技术是 PageRank,即网页排名。PageRank 对链接数目进行加权统计。Larry Page 和 Sergey Brin 两人利用稀疏矩阵技巧,大大简化了计算量。
blog 使得网民不仅是互联网内容的消费者,亦是生产者。
微博是一种互动及传播极快的工具,实时性、现场感和快捷性往往超过所有媒体。
电子邮件两个重要标准:简单邮件传送协议 SMTP (Simple Mail Transfer Protocol) 和互联网文本报文格式。
SMTP 只能传送可打印的 7 位 ASCII 邮件,因此后来又提出通用互联网邮件扩充 MIME (Multipurpose Internet Mail Extensions),可同时传送多种类型数据,数据类型于首部说明。
一个电子邮件系统应有三个主要组成构件:用户代理、邮件服务器、邮件发送协议(如 SMTP)和邮件读取协议(如 POP3)
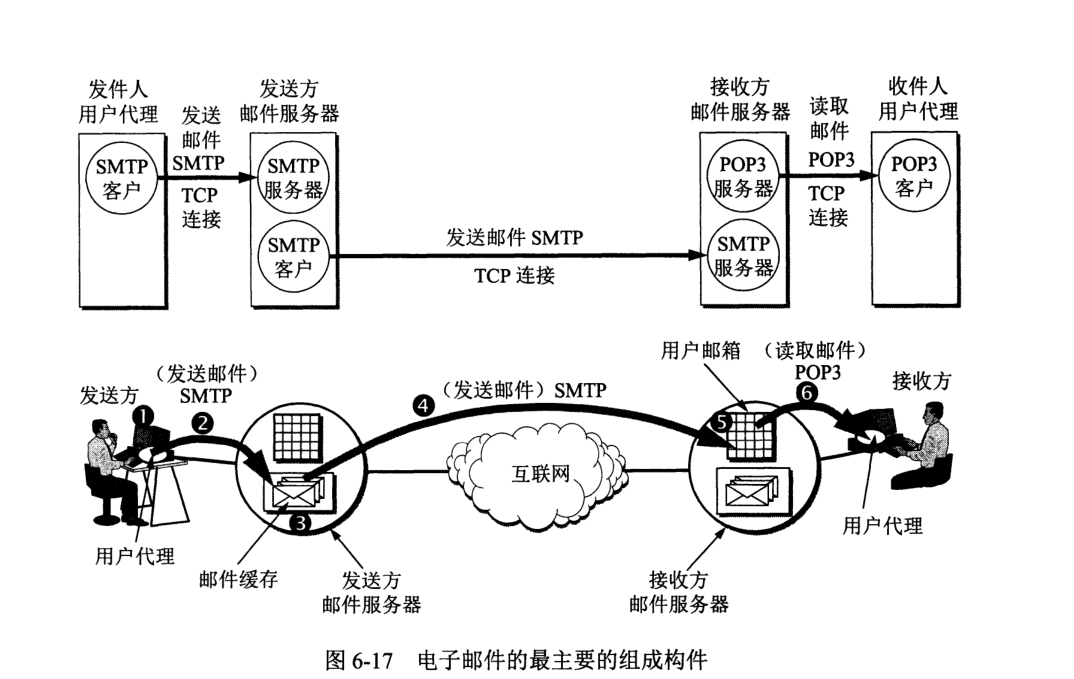
用户代理 UA (User Agent) 是用户与电子邮件系统的接口,又称为电子邮件客户端软件,如 Microsoft Outlook 和张小龙的 Foxmail。
一个 UA 至少应当具有如下四个功能:
互联网上有许多邮件服务器,功能是发送和接收邮件并向发件人报告邮件传送结果,使用两种不同的协议,一种用于 UA 向服务器发送邮件或在服务器间发送邮件,如 SMTP;另一种用于 UA 从服务器读取邮件,如 POP3。
SMTP 和 POP3 都是用 TCP 连接来传送邮件的,使用 TCP 是为了保证可靠性。邮件由发送方服务器与接收方服务器间建立 TCP 连接进行传输,不会在任何中间邮件服务器落地。
整个发送过程有两种不同通信方式,一是推 (push),用于 SMTP 客户将邮件推给 SMTP 服务器;一是拉 (pull),POP3 客户将邮件从 POP3 服务器拉过来。来件暂时存储在用户邮件服务器中,方便时便从服务器中读取来信。
TCP/IP 体系电子邮件系统规定电子邮件地址 (e-mail address) 格式如下:
SMTP 分连接建立、邮件传送、连接释放三部分,TCP 连接总是在通讯双方 SMTP 服务器直接建立,且 SMTP 传输的是明文,不利于保密。后来对 SMTP 进行扩充,称为 ESMTP。客户端发送报文时改用发送 EHLO 报文,若被拒绝则表明对方仍是一个标准的 SMTP 邮件服务器,不支持扩展,就采用原来的参数进行 SMTP 传输。
首部包含一些关键字,最重要的是 To 和 Subject(主题),还有一项是抄送,表明给某某人发送一个副本。某些系统允许用户使用盲复写副本 Bcc (Blind carbon copy),又称暗送,使发件人能将副本送与某人,但不希望为收件人知道。
用户从 POP3 服务器读取了邮件,邮件即从服务器删除。容易猜到会有很多不必要的麻烦,因此 POP3 进行了些功能扩充,包括允许用户设置邮件读取后仍在 POP3 服务器中存放的时间。
IMAP 是一个联机协议,用户打开 IMAP 服务器的邮箱时,可以看到邮件首部。若需要打开某个邮件,则该邮件才传送到计算机上。缺点是如果用户没有将邮件复制到计算机上,则邮件一直存放在 IMAP 服务器中,需上网才能查看邮件。
打开浏览器后即可方便地收发邮件。
浏览器和邮件服务器间传输用 HTTP 协议,但邮件服务器间仍采用 SMTP 协议。
SMTP 有如下缺点:
于是提出通用互联网邮件扩充 MIME,继续用原来的邮件格式,但增加邮件主体结构,定义传送非 ASCII 编码规则。主要包括三部分:
内容传送编码:
在协议软件中给参数赋值的动作叫协议配置。连接到互联网的计算机的协议软件需要配置的项目包括:
用人工进行协议配置很不方便,且易出错,应当采用自动配置方法。现在广泛使用的是动态主机配置协议 DHCP (Dynamic Host Configuration Protocol),提供机制即插即用联网,允许计算机加入新的网络获取 IP 地址而不用手工参与。
DHCP 给运行服务器软件而位置固定的计算机指派一个永久地址,重启时地址不变。
DHCP 采用客户服务器方式。需要 IP 地址的计算机启动时就向 DHCP 广播发现报文 (DHCPDISCOVER)(目的 IP 地址全置为 1),DHCP 服务器回答报文称为提供报文 (DHCPOFFER),先从数据库中查找配置信息,若找到则返回,找不到则从 IP 地址池中取出一个分配之。
每个网络至少有一个 DHCP 中继代理 (relay agent),收到主机 A 的广播发现报文后,就单播向 DHCP 服务器转发报文,收到服务器回答报文后转发给 A。
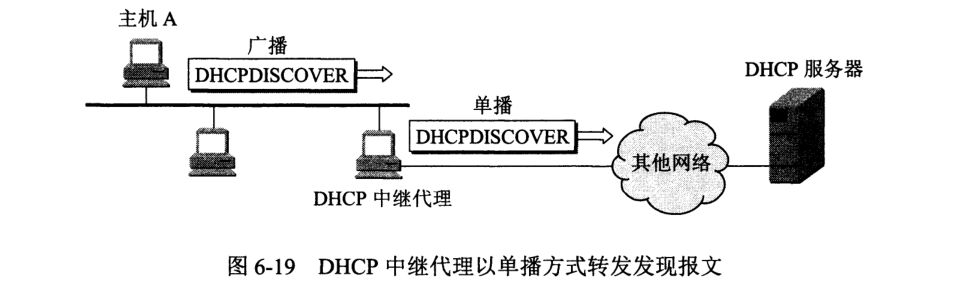
DHCP 客户只能在一段有限时间内使用分配到的 IP,称为租用期 (lease period)。DHCP 客户使用的端口号为 68,服务器用的 UDP 端口是 67。
网络管理包括对硬件、软件和人力的使用、综合与协调,以便对网络资源进行监视、测试、配置、分析、评价和控制,以合理的价格满足网络的一些需求,如实时运行性能、服务质量等。
管理站又称管理器,是整个网络管理系统的核心,通常是个有着良好图形界面的高性能工作站,并由网络管理员直接操作和控制。
管理站所在部门常称为网络运行中心 NOC (Network Operations Center),管理站中关键构件是管理程序,管理站(硬件)或管理程序(软件)均可称为管理者 (manager) 或管理器,网络管理员 (administrator) 才是指人。
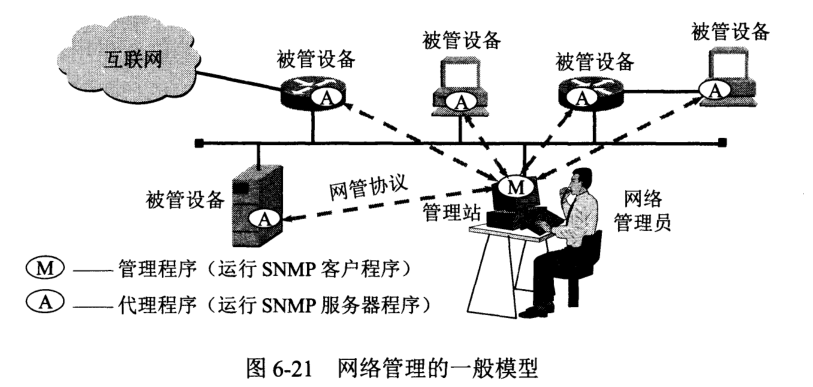
被管网络中有很多被管设备,可以是主机、路由器、打印机、集线器、网桥或网络解调器等。被管设备有时可称网络元素或网元。每个被管设备都要运行一个程序以便和管理站中的管理程序通信,这些程序称为网络管理代理程序或简称代理 (agent)。
简单网络管理协议 SNMP (Simple Network Management Protocol) 中的管理程序和代理按客户服务器方式工作。管理程序运行 SNMP 客户程序,代理运行 SNMP 服务器程序。被管对象 SNMP 服务器不断监听来自管理站 SNMP 客户的请求,一旦发现就立刻返回i信息或执行某个动作。
网络管理基本原理:若要管理某个对象,必然会给该对象添加一些硬件或软件,但这种“添加”对原有对象影响必须小些。
若网元使用的不是 SNMP 而是另一种网管协议,可使用委托代理 (proxy agent) 实现如协议转换和过滤操作等功能对被管对象进行管理。
下将详细介绍 SMI、MIB 和 SNMP。
SMI 建立规则,MIB 对变量进行说明, SNMP 完成网管的动作。
SMI 有三个任务:
采用对象命名树 (object naming tree),根无名。
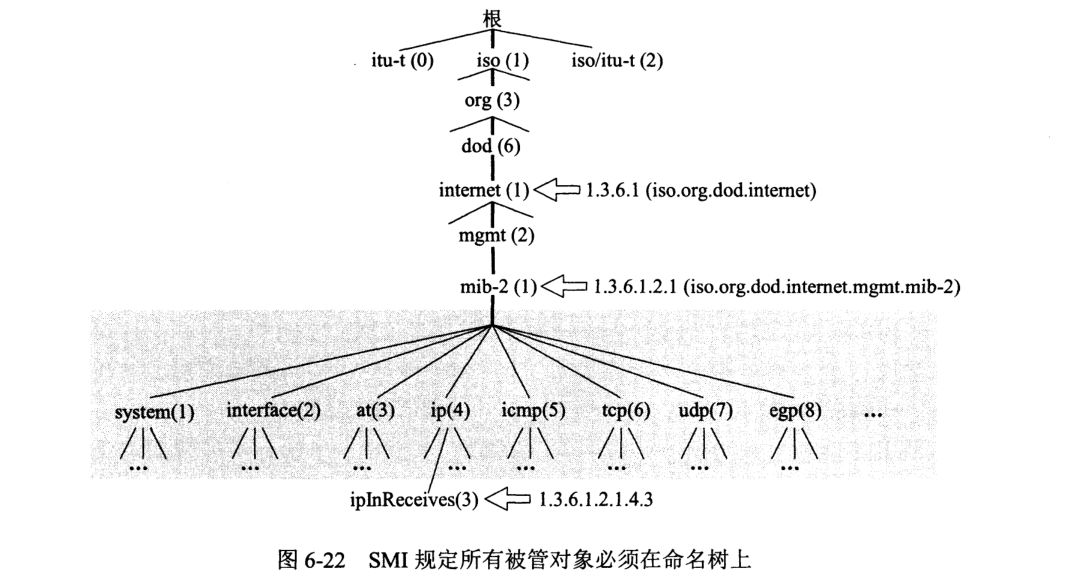
SMI 使用基本抽象语法记法 1 (ASN.1) 来定义数据类型,也增加了一些新的定义。SMI 把数据类型分为两大类:简单类型和结构化类型。
两种结构化类型 sequence 和 sequence of,前者类似于 C 语言的 struct,后者类似于 C 语言的 array。
SMI 使用 ASN.1 制定的基本编码规则 BER (Basic Encoding Rule) 进行编码。把所有数据元素表示为 T-L-V 三个字段,T (Tag) 定义类型,L (Length) 定义 V 字段长度,V (Value) 定义字段的值。
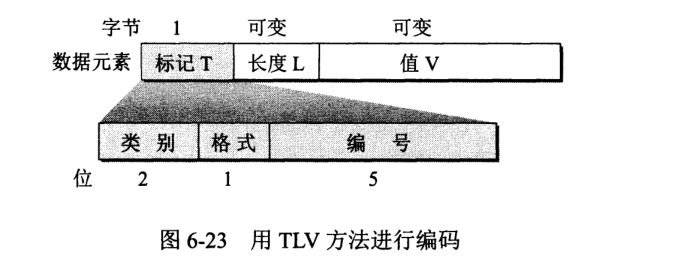
T 字段又称为标记字段,分为如下三个子字段:
管理程序使用 MIB 中信息的值对网络进行管理,只有在 MIB 中的对象才是 SNMP 所能管理的。
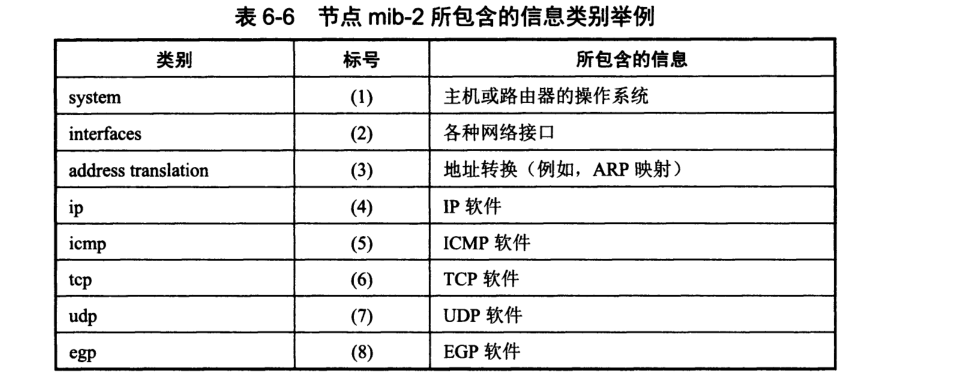
MIB 变量只给出了每个数据项的逻辑定义,而一个路由器使用的内部数据结构可能与 MIB 的定义不同。
SNMP 实际上只有两种基本管理功能:
SNMP 不是完全的探寻协议,允许不经过询问发送某些信息,这些信息称之为陷阱 (trap),能捕捉事件,但参数受限。仅在严重事件发生时才发送陷阱,且陷阱所需字节数很少。
SNMP 使用无连接的 UDP,开销很小。在运行代理的服务器端使用熟知端口 161 接收 Get 或 Set 报文以及发送响应报文,运行管理程序的客户端使用熟知端口 162 接收来自各代理的 trap 报文。
SNMP 报文无固定字段,采用 ASN.1 编码。一个 SNMP 报文由四部分组成:版本、首部、安全参数、数据部分。
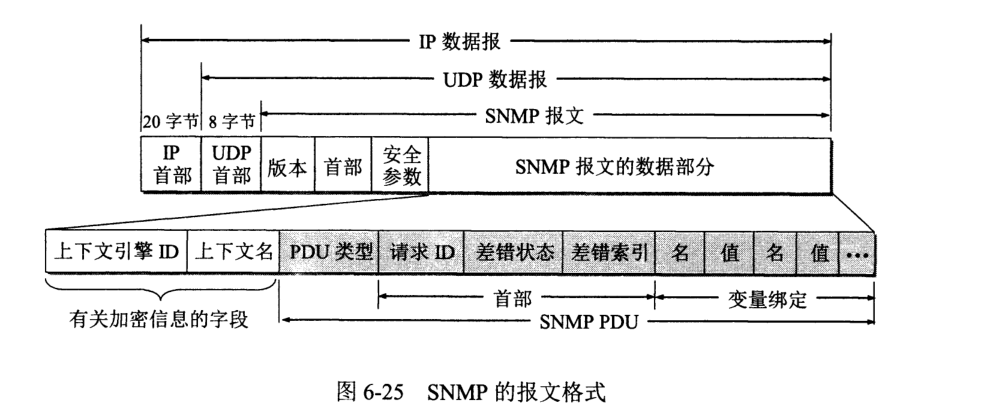
目前互联网流量中,P2P 文件分发已经占据最大份额。
使用 Napster 可通过互联网免费下载各种 MP3 音乐,运行 Napster 的所有用户,都必须及时向 Napster 的目录服务器报告自己已经存有哪些音乐文件。当用户需要时,便向服务器发出查询,服务器返回存有这一文件的计算机 IP 地址。
二代 P2P Gnutella 使用洪泛法在大量 Gnutella 用户间进行查询。其使用了一种有限范围的洪泛查询。
下介绍更后来的技术——比特洪流 BT (Bit Torrent)。BT 把参与某个文件分发的所有对等方称之为一个洪流 (torrent),对等方下载文件的数据单元称为文件块 (block)。
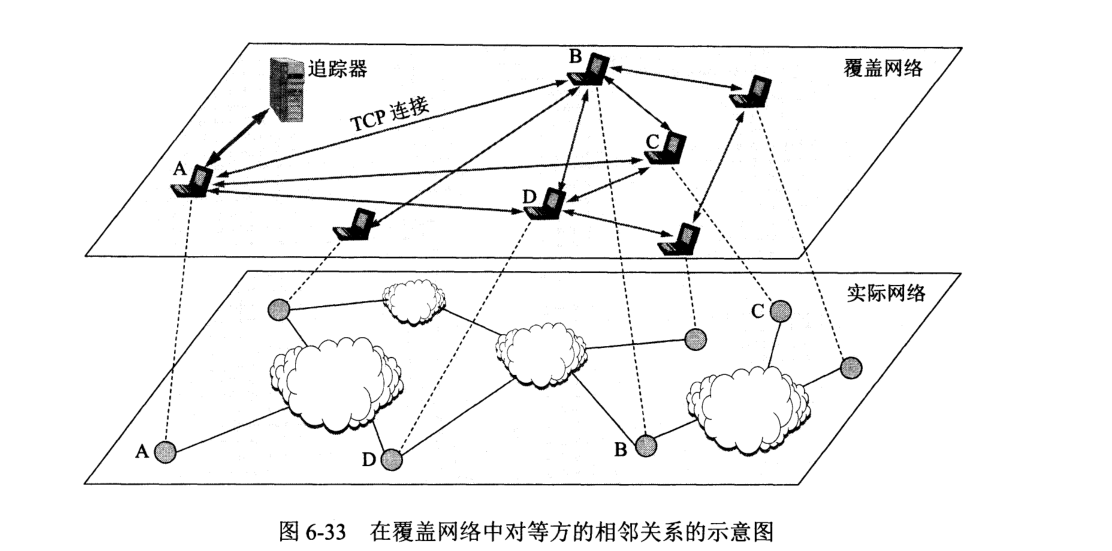
每个洪流有一个基础设施节点称追踪器 (tracker),一个对等放方加入洪流时必须登记(或称注册),并周期性通知其仍处于洪流中。
一个洪流中,文件的需求方和提供方之间通过建立 TCP 连接传输文件块。当一个对等方 A 加入洪流时,追踪器为其指派若干个相邻对等方,A 通过 TCP 连接周期性向相邻对等方索取它们拥有的文件块列表。
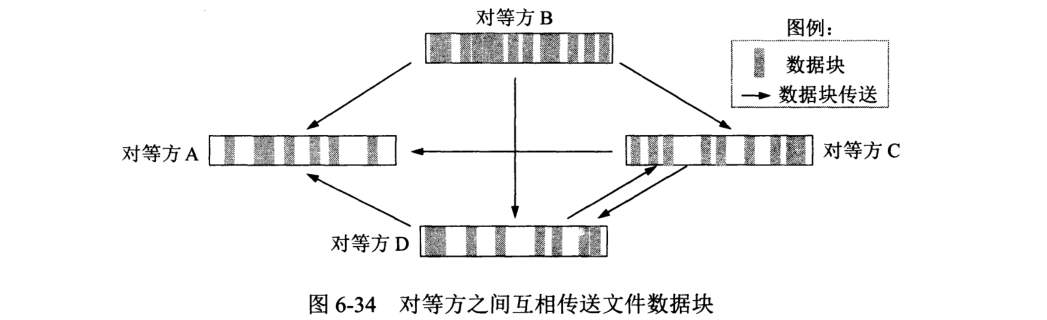
A 必须抉择的是:哪些文件块需要向相邻对等放请求?在众多请求中,应向哪些相邻对等放发送所请求的文件块?
对于前者,A 采用最稀有的优先 (rarest first) 技术,凡是 A 所缺少而相邻对等方已拥有的块,都应当去索取。
对于后者,采用算法:凡当前有以最高数据率向 A 传送文件块的某相邻对等方, A 就优先将请求块传送给它。
数据库中存储信息仅两个部分:资源名 K(又称关键字)、存放该对象的节点的 IP 地址 N(有的 IP 还附有端口号)。
现在广泛使用的索引和查找技术叫分布式散列表 DHT (Distributed Hash Table),是由大量对等方共同维护的哈希表。基于 DHT 的算法如 Chord,把资源名 K 及 IP 地址 N 分别映射到资源名标识符 KID 和节点标识符 NID。把结点标识符从小到大沿顺时针排列成一个环形覆盖网络 Chord 环并按规则映射:
举例说明: K31 和 K2 都放在 N4,表示要找资源 K31 或 K2 的结点的 IP,应当到 N4 去找。即按 K 映射到 KID,从 KID 找到 NID,在 NID 中寻找 IP 地址 N。
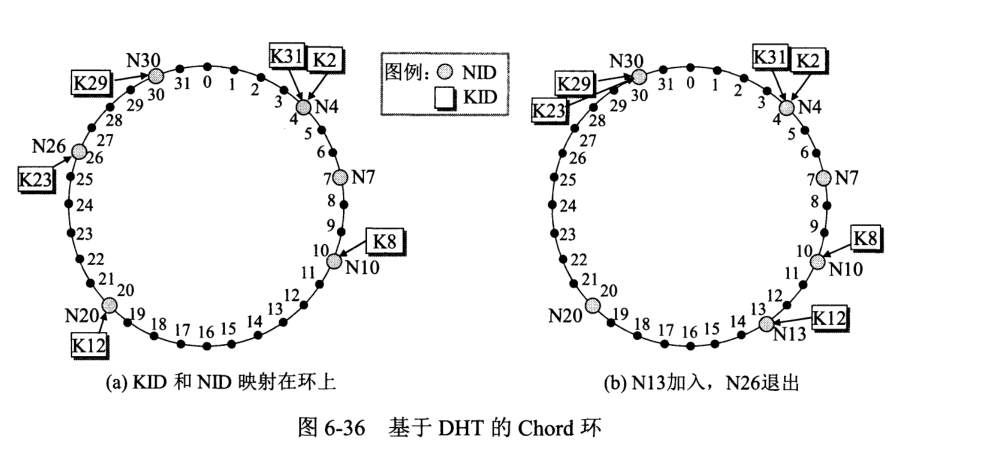
定位一个资源,平均沿环发送查找报文 N/2 个或遍历所有结点,显然效率很低。
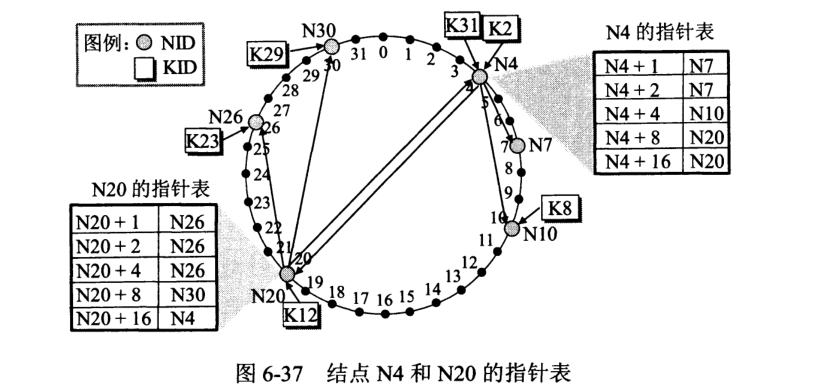
为加速查找,可以采用倍增算法,每个结点 x 指向 $x+1, x+2, x+4, x+8…$ 的结点,这样当欲定位某个编号的结点时,即可在 log 的开销内查找。举例:
当前在结点 $1$,欲定位到结点 $28$,则 $1 + 16 = 17$, $17 + 8 = 25$, $25 + 2 = 27$, $27 + 1 = 28$。
P2P 存在一些关键的问题,一是知识产权,二是 P2P 流量管理,处理网上一些灰色资源,三是网络资源占据。
从 IP 层来说,通讯主体是两台主机。但从运输层的视角来看,真正进行通信的实体一台主机中的一个进程与另一台主机一个的进程。
因此,运输层有一个比较重要的功能——复用 (multiplexing) 和分用 (demultiplexing)。复用是指发送端不同应用程序可以使用同一个运输层传输协议。
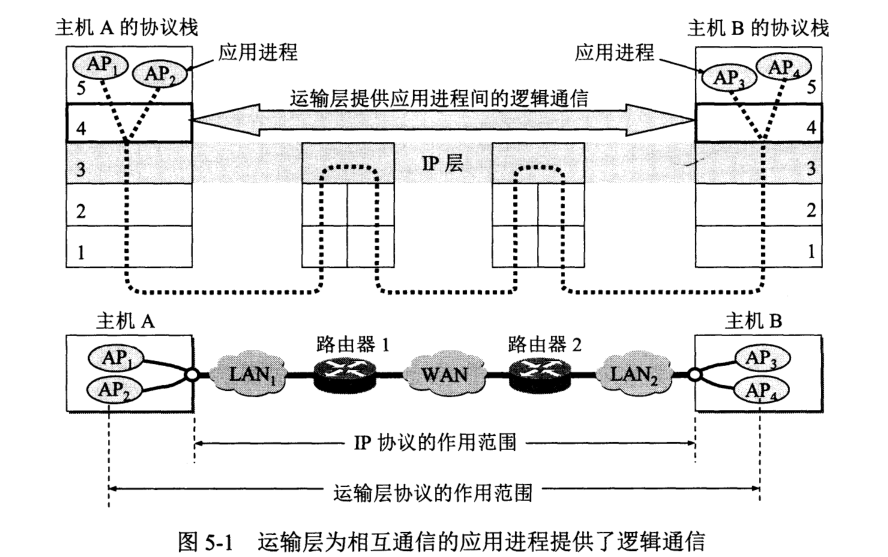
由图观之,网络层为主机之间提供逻辑通信,而运输层为进程之间提供逻辑通信。
单个计算机用的是进程标识符,但由于计算机操作系统种类很多,因此使用该种进程标识符来表示进程并不合适。
此外,由于进程创建撤销均是动态的,通信一方几乎无法识别对方机器上的进程,因而将特定进程指名为终点是不可行的。
解决方案是运输层采用协议端口号 (protocol port number),或简称为端口 (port)。这种抽象的协议端口是软件端口。端口号只具有本地意义,只是为了标志本计算机应用层中的各个进程在运输层交互时的层间接口。不同计算机相同端口号是没有关联的。
运输层端口号分为两大类:
用户数据报协议 UDP (User Datagram Protocol):传输前无需建立连接,不提供可靠交付,且较为简单。
传输控制协议 TCP (Transmission Control Protocol):提供面向连接的服务,但不提供广播或多播服务,较为复杂。
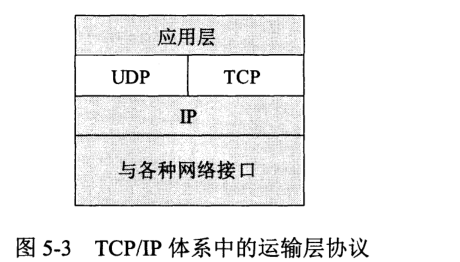
接下来将详细阐述两个协议的内容及要点。
UDP 有主要特点如:
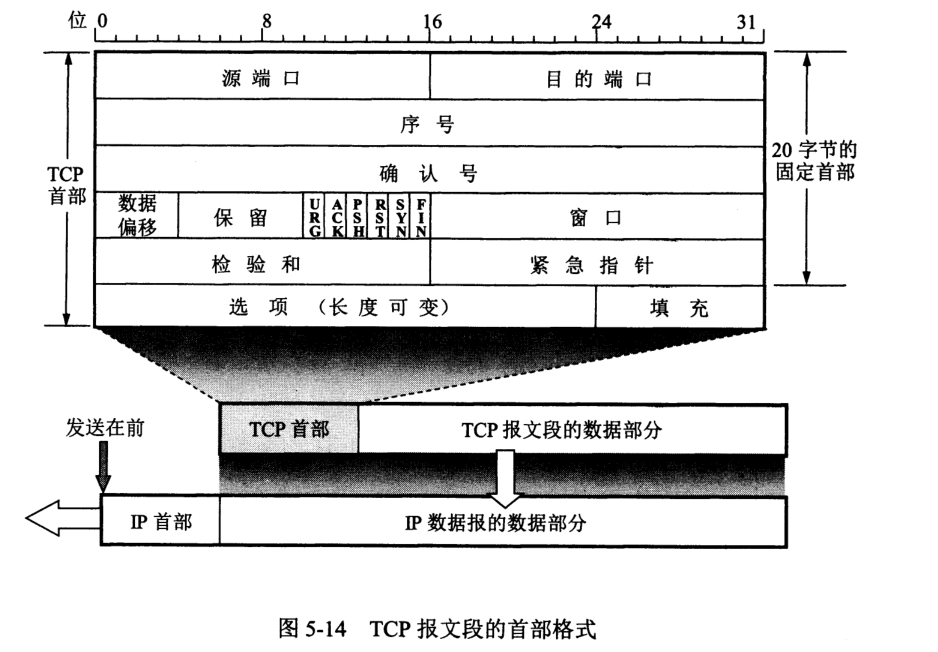
首部格式如图:
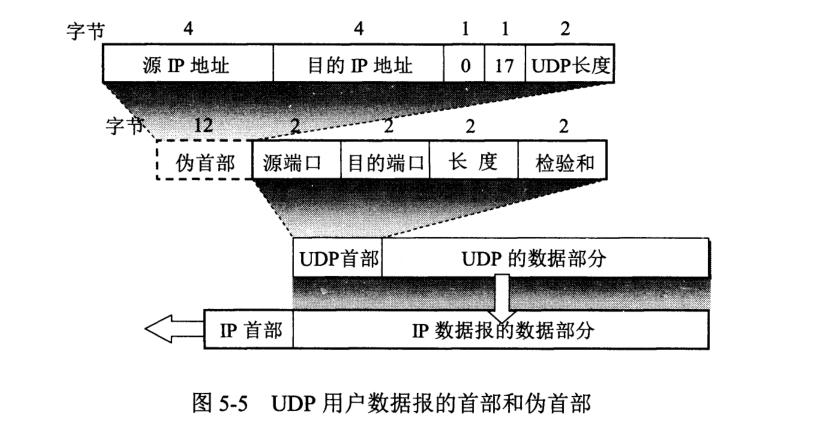
若接收方发现收到端口号不正确,则丢弃并由网际控制报文协议 ICMP 发送”端口不可达“差错报文。
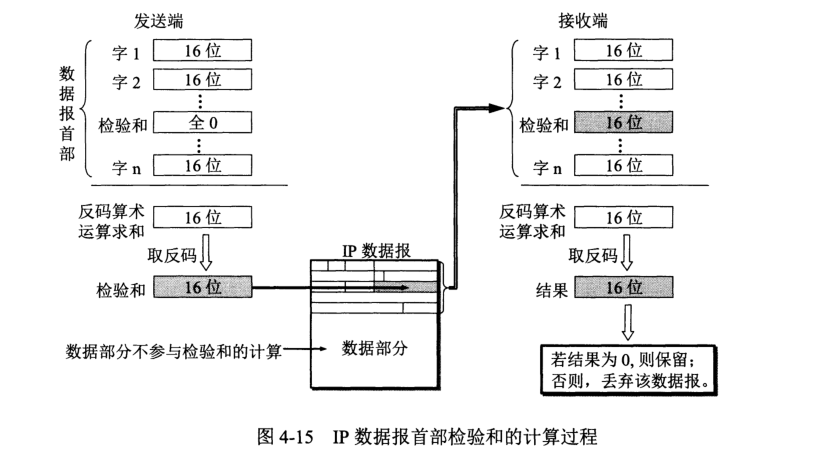
”伪首部“的出现是为了计算检验和,在实际传输中并不存在。检验和为 UDP 数据报每一个 16 位字之和的反码,到接收端再与每一 16 位字相加,最终结果为全 1 即无差错。
TCP 连接的端点叫套接字 (socket) 或插口,我们由:
理想传输条件两大特点:
假定 A 与 B 之间进行通讯。
无差错时,A 发予 B 一个分组,B 接受后对 A 发送该分组的确认,A 收到确认后继续发送下一分组,如此往复。
B 接受到分组时除了差错并丢弃,或是分组在传输中丢失,B 都不会发送任何消息。A 过了一段时间没收到确认,就执行超时重传。为实现超时重传,每发送一个分组设置一个超时计时器。若计时器到期前收到确认,则撤销计时器。
倘如 B 接收到分组 $M_1$,但发回 A 的确认丢失,A 执行重传,B 又收到了相同的分组,此时应作两个动作:
这种可靠传输协议通常称自动重传请求 ARQ (Automatic Repeat reQuest)。
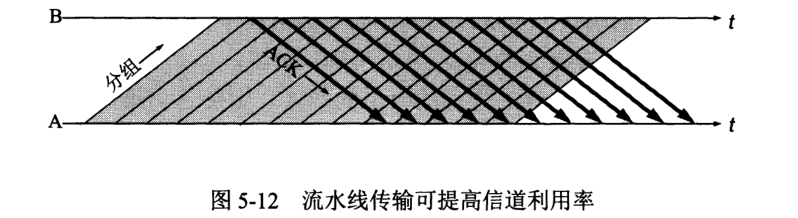
重传协议的优点是简单,但缺点是信道利用率低。
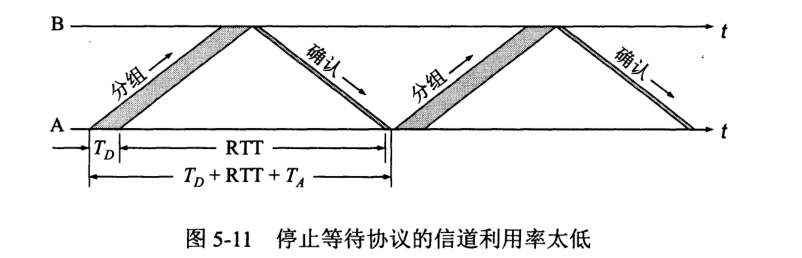
为了提高传输效率,我们采用流水线传输。为此引出下面一堆芝士。
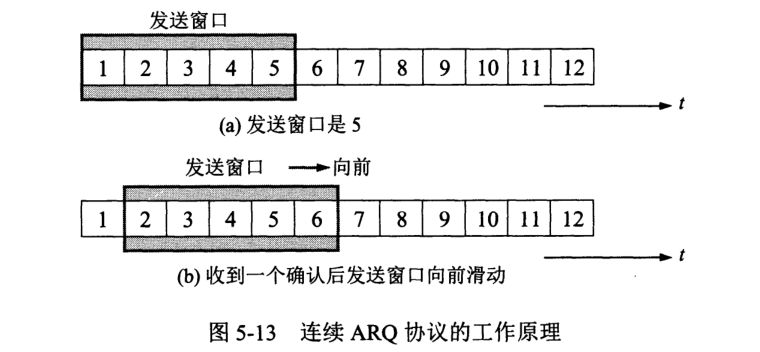
核心概念是窗口,窗口大小设定为 size。
每次,发送端将窗口内连续的分组全部发送出去,接收端采用累计确认方式,对按序到达的最后一个分组发送确认。发送端每收到一个确认,就进行调整把滑动窗口前移。
若确认号 = N,则表明:到序号 N-1 为止所有的数据都已经收到。
TCP 滑动窗口也有可能后缩,但 TCP 标准墙裂不推荐这么做。重传机制已如上讲述。
发送缓存暂时存放:
接收缓存暂时存放:
对于未按序到达的数据,TCP 标注并无明确规定如何处理。一般是待缺失的数据流收到后,再按序交付上层。
采用自适应算法。RTT:往返时间。RTO:超时重传时间。
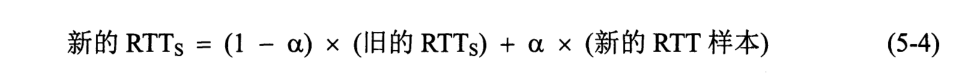

Karn 算法及修正:计算加权 RTTS 时,不考虑重传段。每重传一次,将 RTO 加倍。
流量控制就是让发送方发送速率不要太快,让接收方来得及接收。
发送方的窗口不能超过接收方给出的接收窗口的数值。

若 B 向 A 发送零窗口后, 又有了存储空间,继续发送 rwnd = 400 的报文段,却于传输途中丢失,A 一直等待 B 的通知,而 B 也一直等待 A 的报文段,若没有其它措施,死锁局面将一直持续下去。为此,TCP 为每个连接设有一个持续计时器 (persistence timer)。只要一方收到对方零窗口通知则启动计时器,时间到期则发送零窗口探测报文段(仅携带 1 字节数据)。若窗口值确实为 0,就重置,否则死锁局面被打破。
TCP 的实现广泛使用 Nagle 算法:若进程把数据逐字节发送到 TCP 缓存,则发送方把第一个数据字节先发送出去,把后面到达的全部缓存。当收到第一个数据字符确认后,再把缓存中所有数据组装成一个报文发送出去,对随后到达的数据缓存。仅当收到前一个段的确认后才发送下一个段。当到达数据已经到达发送窗口大小一般或最大报文长度,就立即发送。 这种算法可以有效提高网络吞吐量。
窗口糊涂综合征:TCP 接收方缓存已满,而交互式应用进程每次只从接收缓存中读取 1 字节。接收方发回确认,将窗口置位 1 字节。如此下去,效率很低。为解决此问题,可以让接收方等待一段时间,待缓存能容纳一个最长报文段或有一半闲余空间,发出确认报文,并通知当前窗口大小。
拥塞控制即防止过多数据注入到网络中,可以使网络中路由器或链路不至过载。
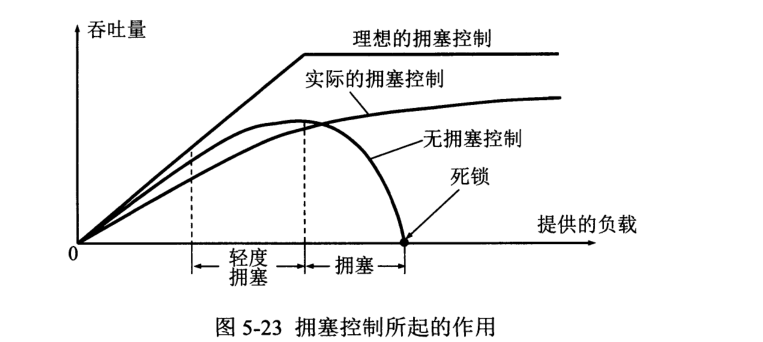
拥塞控制分为开环控制与闭环控制两种。开环控制是在设计网络时事先将有关发生拥塞的因素考虑到,但系统运行后就不做改变了。
闭环控制基于环路反馈,有如下措施:
慢开始、拥塞避免、快重传、快恢复四种算法。
用报文段个数作为窗口大小单位,每经过一个传输轮次,cwnd 加倍。SMSS (Sender Maximum Segment Size) 是指发送方的最大报文段。
实际操作中,慢开始和拥塞避免是配合使用的。设定一个 ssthresh 值,cwnd 小于该值,用慢启动;cwnd 大于该值,用拥塞避免;等于二者均可。
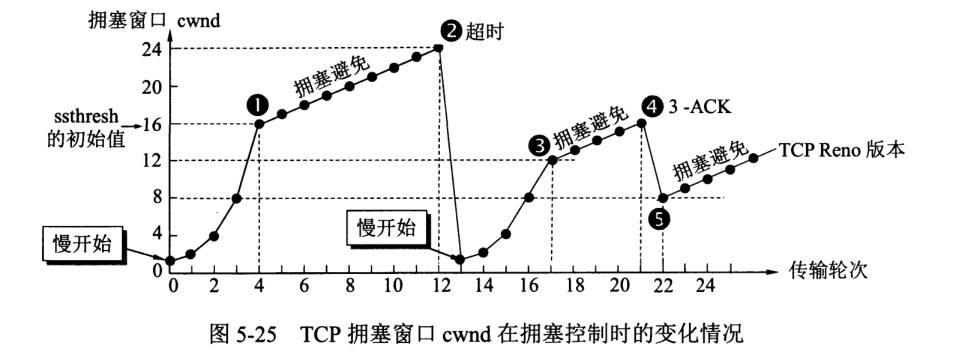
超时则门限值置为当前 cwnd 的一半。当 B 端收到无序帧时,仍然发送对最前端已确认帧的确认,当 A 端收到一连三个确认帧,即可视为发生了数据丢失。
快恢复算法:发送端得知丢失个别报文段,便不进行慢启动,二是置拥塞窗口 sstresh = cwnd = cwnd / 2,并执行拥塞避免算法。
拥塞避免阶段窗口线性增大,称为加法增大 AI (Additive Increase)。出现拥塞将门限值调整为原来一半,称为乘法减小 MD (Multiplicative Decrease)。二者结合即 AIMD 算法。
同时发送窗口不得超过接收端窗口上限 rwnd。故有:
路由器队列管理通常按照先进先出 FIFO 规则处理到来数据,当队列满时丢弃后续到达所有分组,称为尾部丢弃策略。但这种做法会导致短时间内大量连接同时进入满开始阶段,称为全局同步 (global syncronization)。
为避免这种情况。出现了主动队列管理 AQM (Active Queue Management),当队列长度达到某个警惕值时丢弃到达分组。曾流行的实现方法是随即早期检测 RED (Random Early Detection),描述如下:
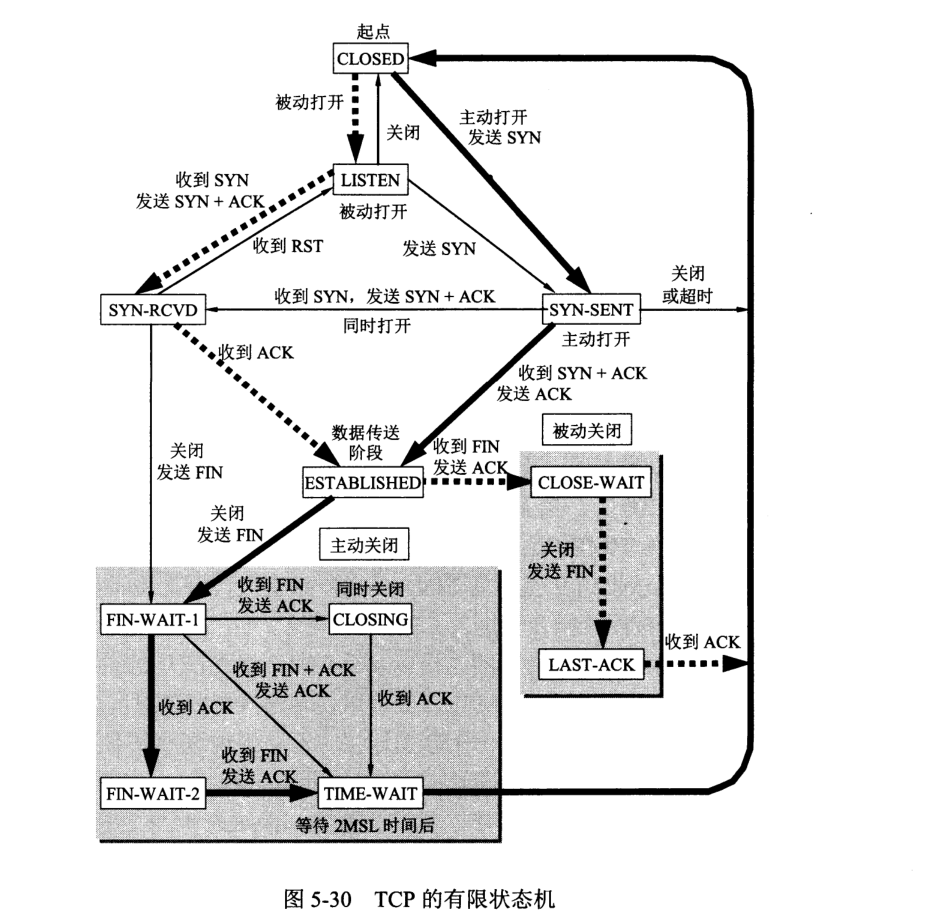
主动发起连接的进程称为客户 (client),被动等待连接的进程称为服务器 (sever)。
三次握手协议:(来自亲爱的 ChatGPT)
此外,TCP 设有一个保活计时器,每个一段时间发送探测字段,若一连几个都收不到回应,则关闭连接。
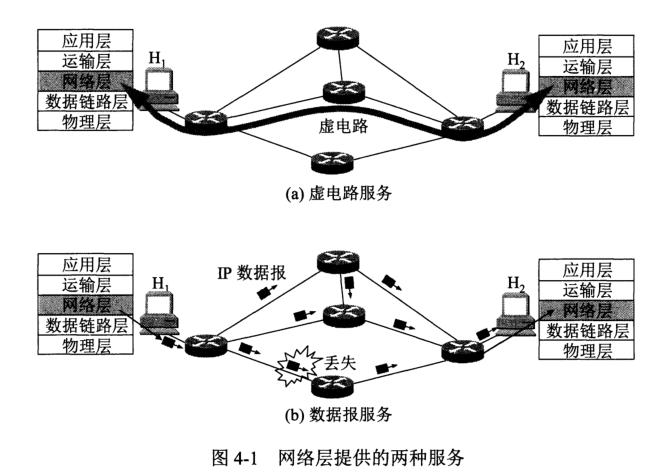
电信网采用面向连接的通信方式,并在此基础上使用可靠传输协议,当有通信需求时,双方建立虚电路进行实时通讯,通讯结束后释放通讯资源。由于终端电话机结构简单,无处理差错能力,因此此方案对电话业务来说是十分合适的。
但计算机网络的终端具有很强的处理差错能力,因此网络层的设计思路为:网络层向上只提供简单灵活的、无连接、尽最大努力的数据报服务。网络层不提供服务质量的承诺,可靠传输由网络主机中的运输层保障。

与 IP 协议配套的三个协议:
三协议关系如下:
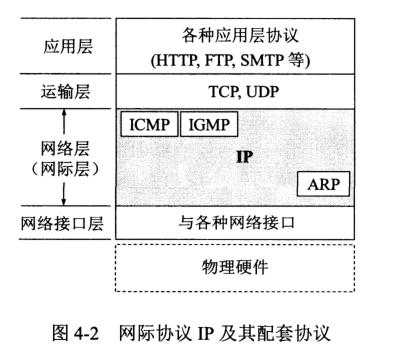
TCP/IP 协议中的网络层常常被称为网际层或 IP 层。
没有一种单一的网络能够适应所有用户的需求。将网络连接起来需要一些不同的中间设备,一般有如下四种:
由于历史原因,许多 TCP/IP 的文献曾把网络层使用的路由器称为网关。
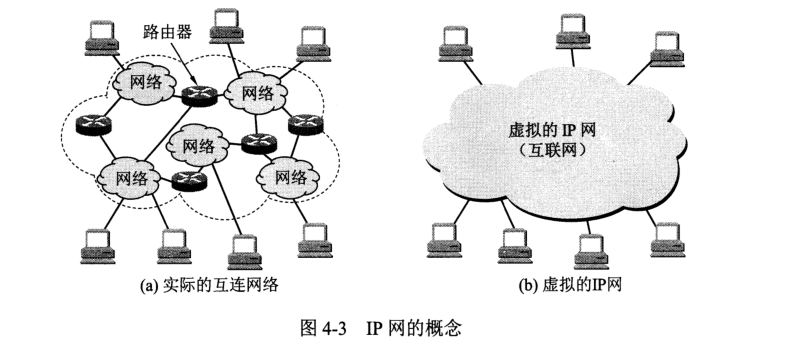
参与互连的计算机网络都是用相同的网际协议 IP,因此可以看作一个大的虚拟互连网络。
其中 D 类地址用于多播。
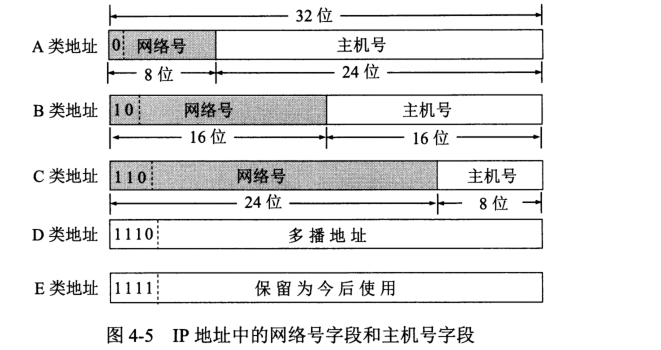
点分十进制表示法:32 位 IPv4 地址,八位一段点分隔,每段十进制表示。
常用的三种类别 IP 地址
A 类地址:
B 类地址:
两个路由器相连,在连线两端的接口处可分配也可不分配 IP 地址。节省资源则不分配,常称为 无编号网络或无名网络。
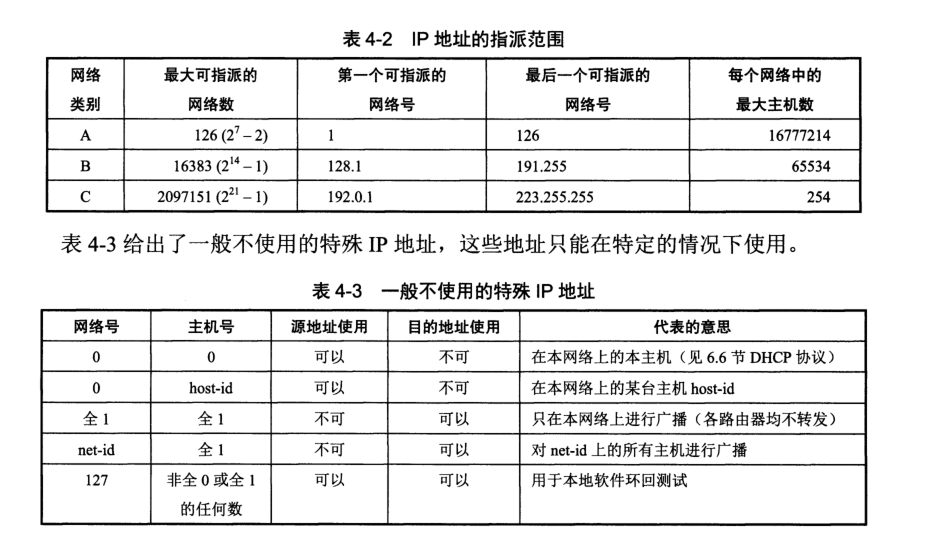
物理地址是数据链路层和物理层使用的地址,而 IP 地址是网络层和以上各层使用的地址,是一种逻辑地址。
在通讯过程,数据从高层下到低层,层层封装,然后才到链路上传输。设备在收到 MAC 帧时,根据首部硬件地址决定收下或丢弃。
IP 层抽象的互联网上只能看到 IP 数据报。
虽然 IP 数据报有源地址,但路由器只根据目的站 IP 地址的网络号进行路由选择。
知道 IP 地址,找出其相应的硬件地址。ARP 在主机 ARP 高速缓存 (APR cache) 中存放一个有本局域网上的各主机和路由器 IP 到硬件地址的映射表,并且映射表经常动态更新。
当 A 向 B 发送 IP 数据报时,先在其 ARP cache 中查找,若查不到,则 ARP 进程广播 ARP 请求分组,除 B 外的主机不响应,B 则响应并向 A 发送 ARP 响应分组(单播),且 B 也将 A 的物理地址写入 cache 中。
ARP 解决的是同一个局域网上的映射问题。
路由表信息:
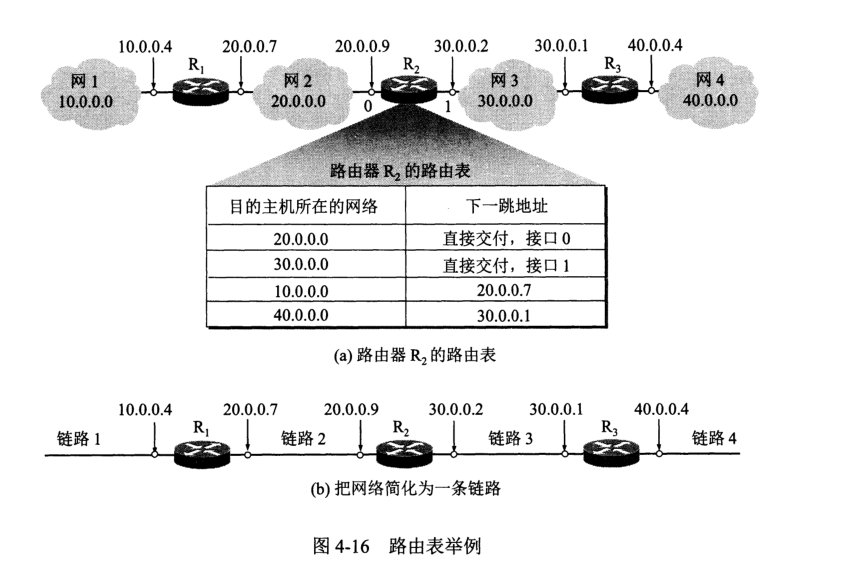
存在特定主机路由,对特定的主机指明一个路由,以便管理人员控制网络和测试网络。
存在默认路由,减小路由表所占的空间和搜索路由表所用的时间。
默认路由(Default Route)是网络中的一种路由设置,用于指定当路由表中没有匹配的路由项时,数据包应该被发送到的下一个跃点或下一跳。默认路由通常用于简化路由表,特别是在大型网络中。
在IPv4网络中,默认路由通常使用0.0.0.0/0表示,这表示所有目标地址。当路由表中没有与目标地址匹配的具体路由项时,数据包将被发送到默认路由指定的下一个跃点。这有助于简化路由表,特别是在较大的网络中,减少路由表的大小和复杂性。
在IPv6网络中,类似的概念是使用::/0来表示所有IPv6地址。当没有与目标IPv6地址匹配的具体路由项时,数据包将被发送到默认路由指定的下一个跃点。
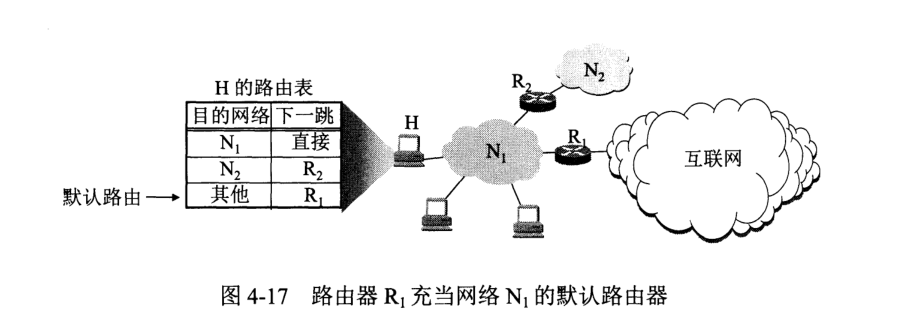
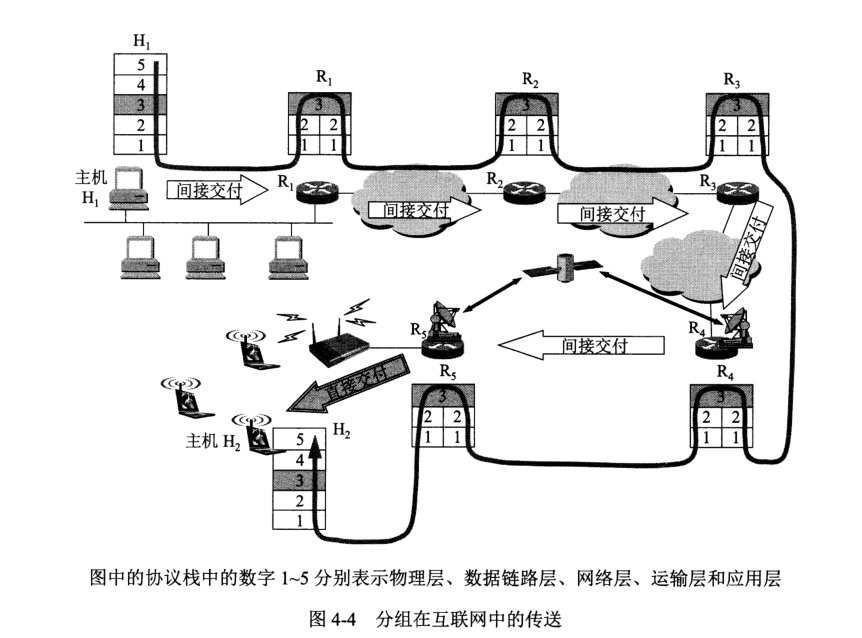
分组转发算法的流程:
IP 地址设计不合理之处:
划分子网的方法:
从 IP 数据报首部无法看出源主机或目的主机所连接的网络是否进行了子网划分,子网掩码正是用于解决这个问题的。
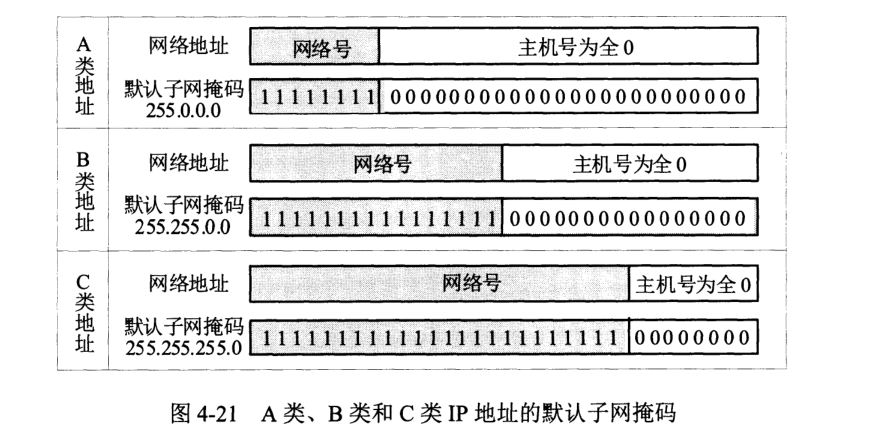
子网掩码一般由一串连续的 1 和一串连续的 0 构成,且 1 的长度等于网络号与子网号位数之和,因此与 IP 地址进行与操作即可得出子网地址。 如果一个网络不划分子网,则使用默认子网掩码,显然,
A 类地址默认掩码为 255.0.0.0,或 0xFF000000。
B 类地址默认掩码为 255.255.0.0,或 0xFFFF0000。
C 类地址默认掩码为 255.255.255.0,或 0xFFFFFF00。
路由表包含:目的网络地址、子网掩码和下一跳地址。
网络前缀相同的连续 IP 地址组成一个 ”CIDR 地址块”。
CIDR 使用斜线激发,即 IP 地址后加上斜线 “/”,后写上前缀位数。
CIDR 还使用 32 位的地址掩码,其中前一串 1 就代表前缀。
路由表中用 CIDR 地址块来查找目的网络,称为路由聚合或构造超网。
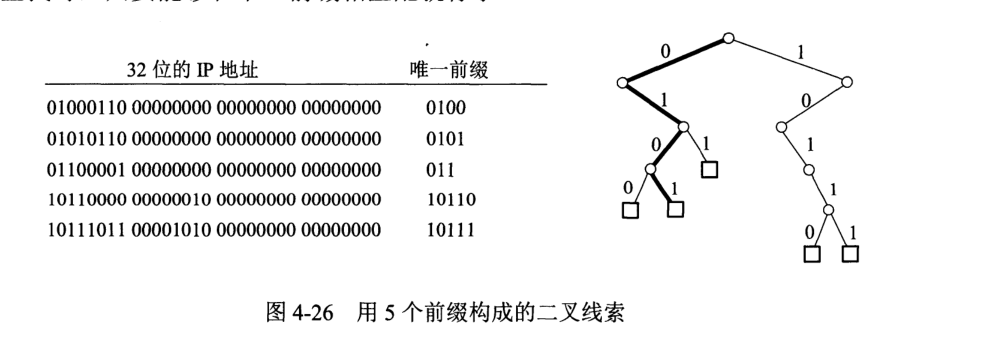
在查找下一跳时,可能有多个 CIDR 地址块都能够与目的地址匹配,此时则根据最长前缀匹配原则确定下一跳。
由于要进行最长前缀匹配,故最方便的方法即是在构造路由表时采用二叉线索,即 01-Trie,然后查询时即可迅速进行前缀匹配。
为了提高效率,还可采用各式压缩技术。
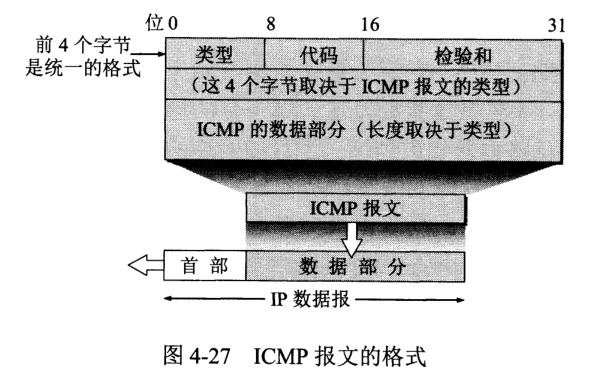
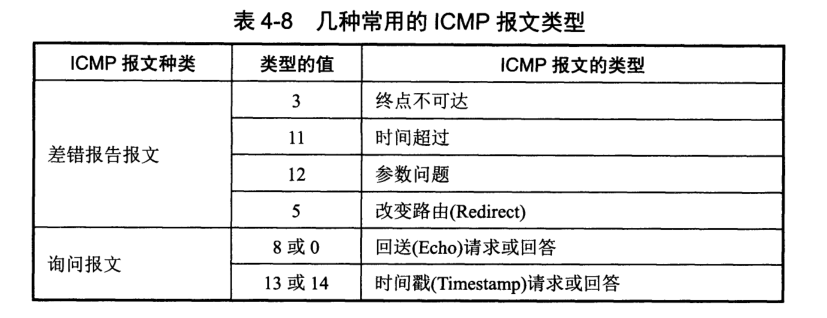
ICMP 报文分为 ICMP 差错报告报文和 ICMP 询问报文。
ICMP 报文前 4 个字节是统一的格式,三个字段:类型、代码和检验和。接着 4 个字节与 ICMP 类型有关。最后面是数据字段,长度取决于 ICMP 类型。
改变路由(重定向): 路由器把改变路由报文发送给主机,让主机知道下次该将数据报发送给另外的路由器(可通过更好的路由)。
不应发送 ICMP 差错报告的情况:
ICMP 的一个重要应用就是分组网间探测 PING (Packet InterNet Groper),是应用层直接使用网络层 ICMP 的一个例子。
另一个重要应用是 traceroute (UNIX) / tracert (windows),用于跟踪一个分组源点到终点的路径。下介绍其原理:
主要采用数据报中的生存时间 TTL,先发送 TTL 为 1,收到时间超过差错报文则 TTL + 1 重新发送,否则收到终点不可达报文,且长度即 TTL。
理想路由算法几个特点:
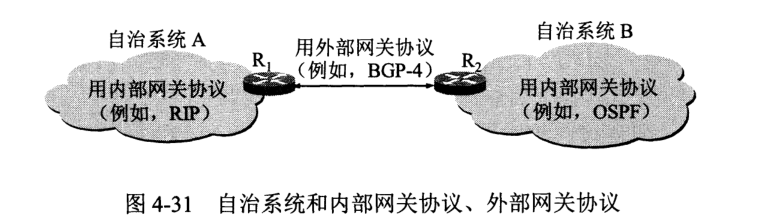
互联网采用分层次的路由选择,原因:
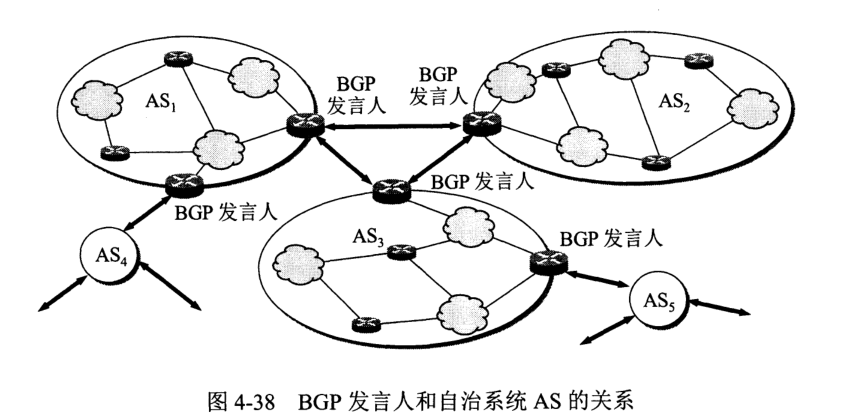
为此,把互联网划分为许多小的自治系统 AS (autonomous system)。一个 AS 对其他的 AS 表现出的是一个单一的和一致的路由选择策略。
故此,路由选择协议可以划分为两类:内部网关协议 IGP (Interior Gateway Protocol) 和外部网关协议 EGP (External Gateway Protocol)。常用的 IGP 有 RIP 和 OSPF 协议,常用的 EGP 有 BGP-4。
此外,路由选择协议还可依照路由表更新方分为静态路由协议和动态路由协议,常见的动态路由协议有 RIP、OSPF、BGP 等。
RIP 是一种基于距离向量的路由选择协议,最大优点是简单。其中的“距离”是指“跳数” (hop count)。但 RIP 一条路径最多只能包含 15 个路由器,因此 RIP 只适用于小型互联网。
RIP 特点:
路由表信息为:
下介绍路由更新算法:

其实就是 Bellman-Fold 算法,不断遍历,能松弛即松弛。
对于解释 3,书中的解释是无论距离是增大减小亦或不变,都要更新为最新的信息。
RIP 报文格式:
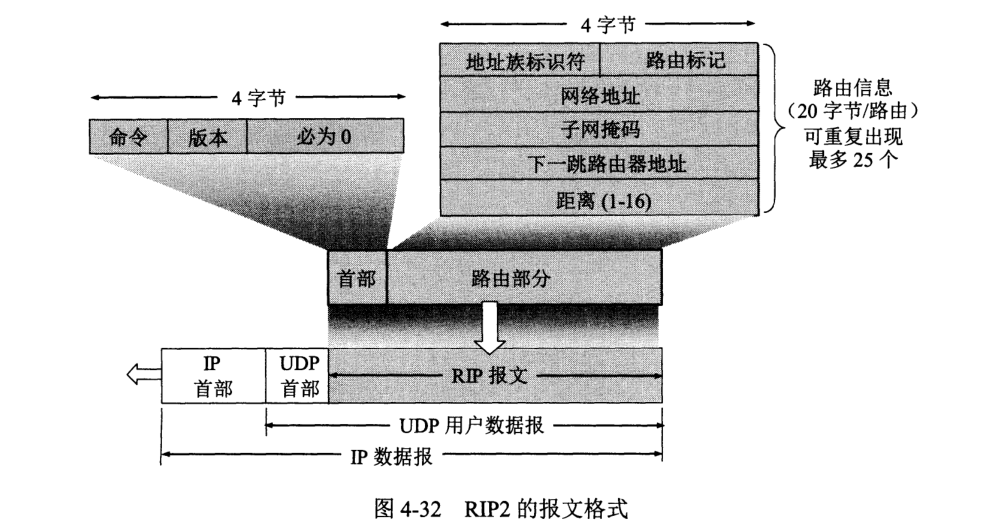
首部 4 字节,命令字段指出报文意义。
路由部分由若干路由信息组成,每个路由信息 20 字节。
一个 RIP 报文最多 25 个路由,故而最大长度 $4+20\times 25=504$ 字节。
RIP 存在的问题:当网络出现故障,需要经过比较长的时间才能将此信息传送到所有的路由器。

RIP 特点总结:实现简单开销小,距离有限,坏消息传播慢。
OSPF 开放最短路径优先 使用了 Dijkstra 提出的最短路径算法 SPF。OSPF 三个要点如下:
由此,每个路由器都能够得到本网完整的网络拓扑,采用 djikstra 算法即可得出最短路径从而构造路由表。
而且 OSPF 将一个自治系统再划分为若干个小的范围,称为区域 (area)。连接不同区域的路由器叫区域边界路由器。主干区域的路由器称主干路由器。OSPF 不用 UDP 而是直接用 IP 数据报传送。
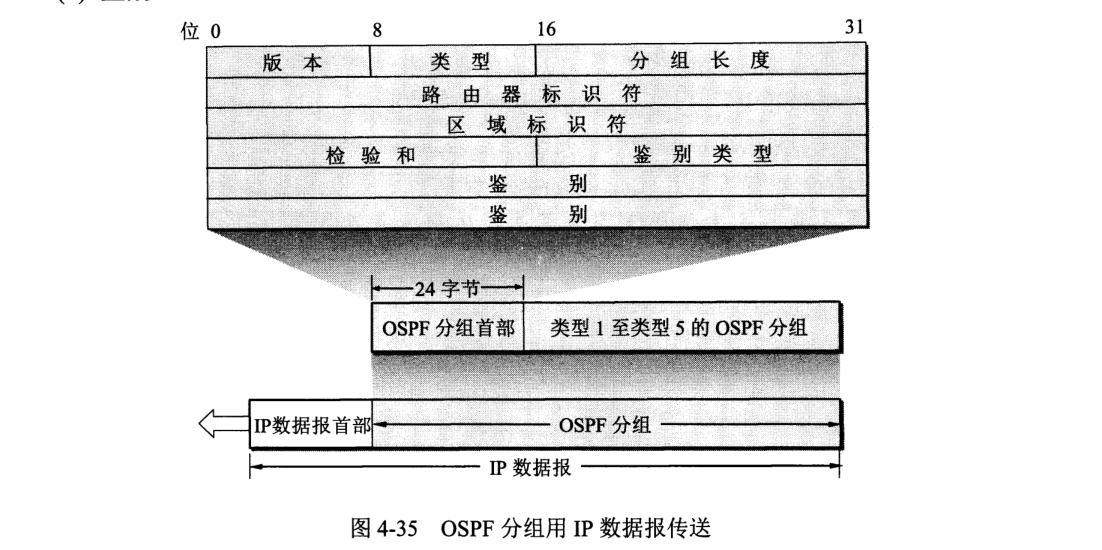
OSPF 其它特点:
OSPF 五种分组类型:
类型2 数据库描述 (Database Description) 分组,向邻站给出自己库中所有链路状态项目的摘要。
类型3 链路状态请求 (Link State Request) 顾名思义
边界网关协议 BGP。不同自治系统之间使用 BGP 的缘由:
BGP 的目的寻找一条能够到达目的且网络条件比较好的路由而非最佳路由,采用路径向量 (path vector) 路由选择协议。每个自治系统至少选定一 BGP 发言人,往往选定边界路由器。发言人之间采用 BGP 协议。
在 RFC 4271 中规定了 BGP-4 的四种报文:
BGP 报文格式:
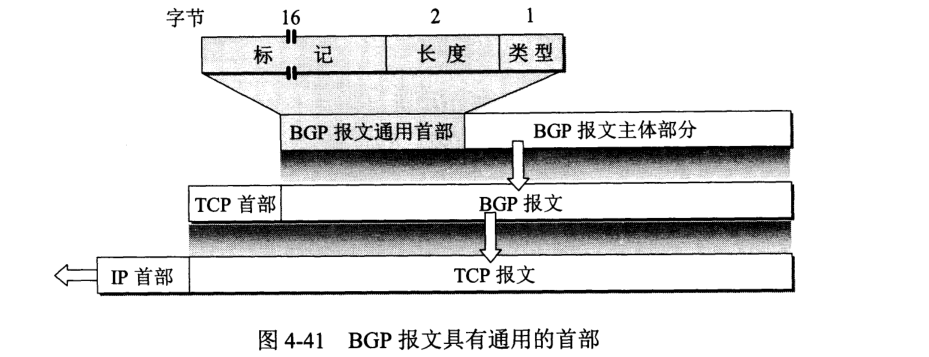
标记 (marker) 段 16 字节长,用于鉴别,不需鉴别是置全 1。
长度字段指出包括首部在内整个 BGP 报文字节为单位的长度,最小 19,最大 4096。(查了下,是根据 TCP 协议的滑动窗口决定的 这里)
UPDATE 和 OPEN 报文的格式暂时不赘述。
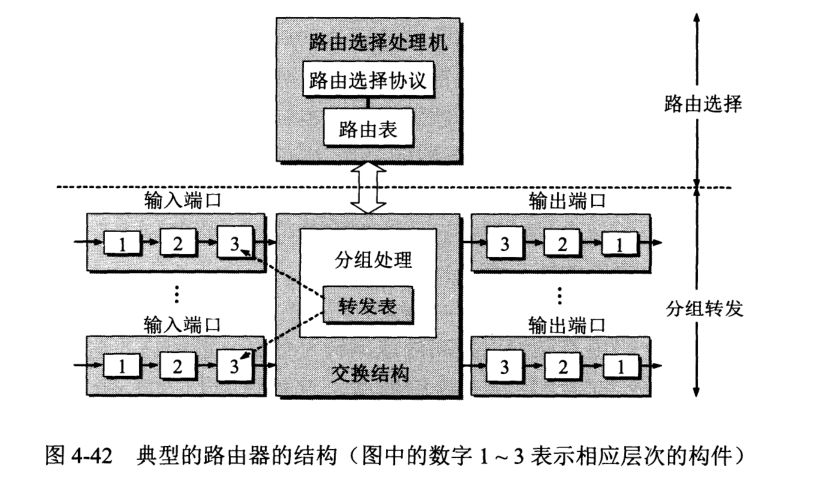
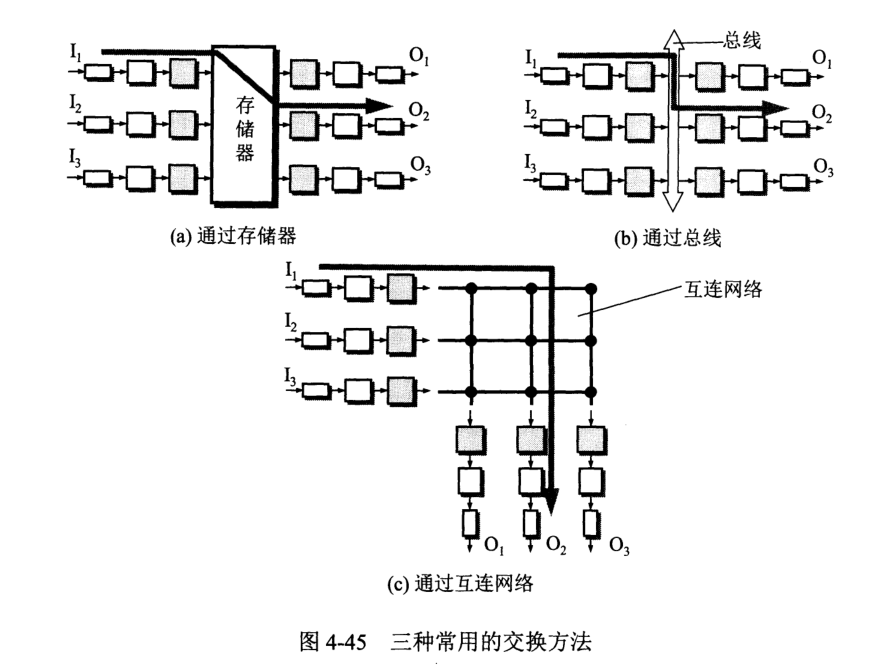
路由器结构划分为两大部分:路由选择部分和分组转发部分。
路由选择部分也称为控制部分,核心构建为选择处理机,任务是根据协议构造出路由表,同时不断更新维护路由表。
分组转发部分有三部分组成:交换结构、一组输入端口和一组输出端口。
交换结构 (switching fabric) 又称交换组织,作用是根据转发表处理分组,把输入的分组从魔偶个端口输出出去。
为了使交换功能分散化,往往把复制到转发表放在每个输入端口中,称为“影子副本”。
最早使用的路由器是普通的计算机,采用 CPU 作为路由选择处理机,利用中断机制启动处理。
变化:
IPv6 数据报有 基本首部和有效载荷两部分组成,有效载荷也成为净载荷。有效载荷允许零个或多个扩展首部。
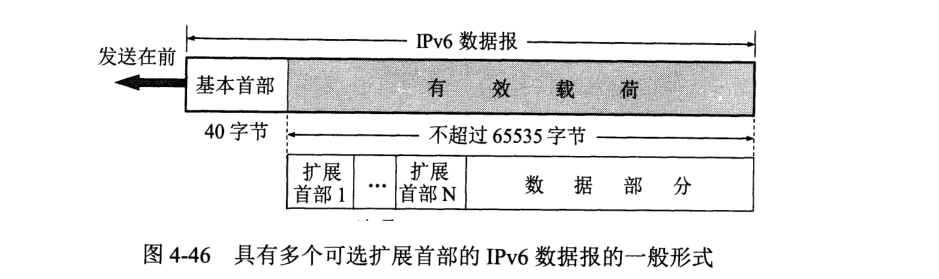
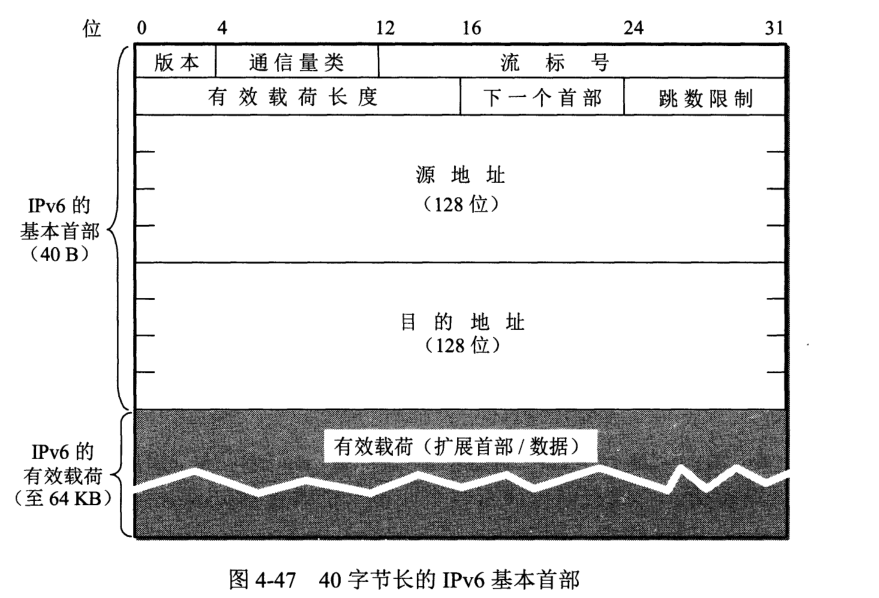
扩展首部在传输中不进行处理,交给两端计算机处理,大大提高路由器处理效率。
IPv6 增加了任播 (anycast) 地址,终点是一组计算机,但数据报只交付其中一个,通常是最接近一个。
IPv6 采用冒号十六进制记法,如
地址分类:

策略一:双协议栈。装有双协议栈的主机或路由器既能与 IPv4 主机通信,又能与 IPv6 主机通信。根据域名系统 DNS 返回的地址类型确定主机使用的地址类型。
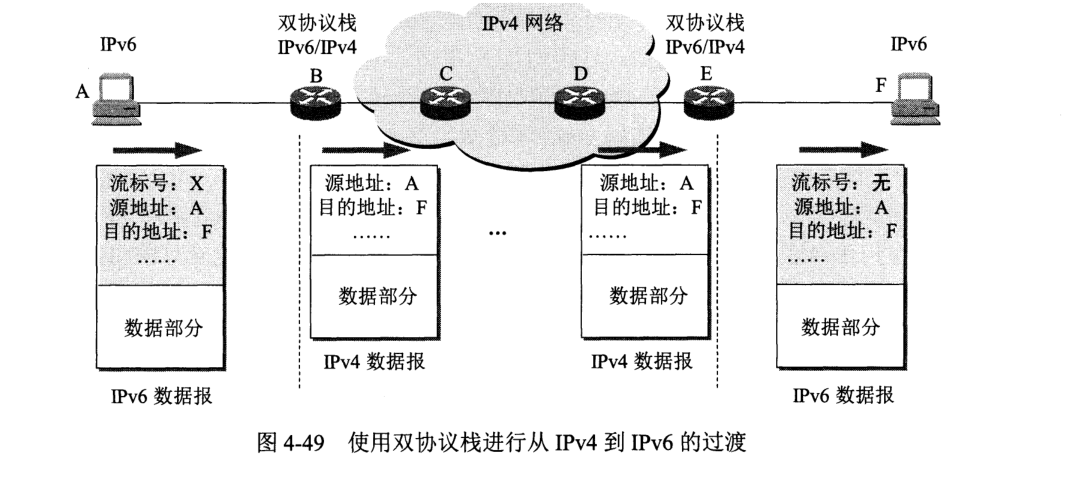
策略二:隧道技术。IPv6 数据报进入 IPv4 网络时,把 IPv6 数据报封装成 IPv4 数据报。要使得双协议栈主机知道 IPv4 数据报内封装的时 IPv6 数据报,则需要将 IPv4 首部的协议字段值设置为 41。
IPv6 也不保证数据可靠交付,因此采用 ICMP 来反馈差错。
与单播相比,一对多的网络通信中,多播可大大节约网络资源。
多播组的标识符是 IP 地址中的 D 类地址,范围是 224.0.0.0 到 239.255.255.255。多播地址只能用于目的地址而不能用于源地址。一个 D 类地址表示一个多播组。
IGMP (Internet Group Management Protocol) 网际组管理协议:是让连接在本地局域网上的多播路由器知道本局域网上是否有主机参加或退出了某个多播组。
多播路由选择协议:多播转发必须动态适应多播组成员的变化,在转发数据报时,不能仅仅根据数据报中的目的地址,而是考虑从什么地方来到什么地方去。
IGMP 属于整个网际协议 IP 的一个组成部分。
多播路由选择协议:洪泛与剪除、隧道技术、基于核心的发现技术。
RFC 1918 指明了一些专用地址,只用于机构内部通信,互联网中所有路由器对目的地址为专用地址的数据报一律不予转发。
VPN 的作用是对内部数据报进行加密,然后在公网上传输,使得效果跟内网通信一样。
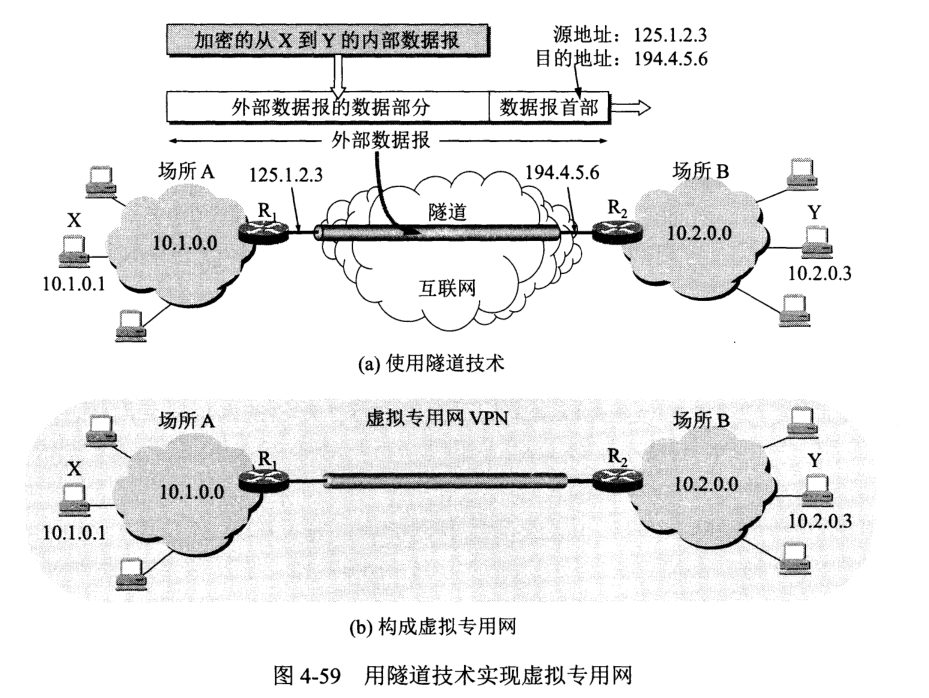
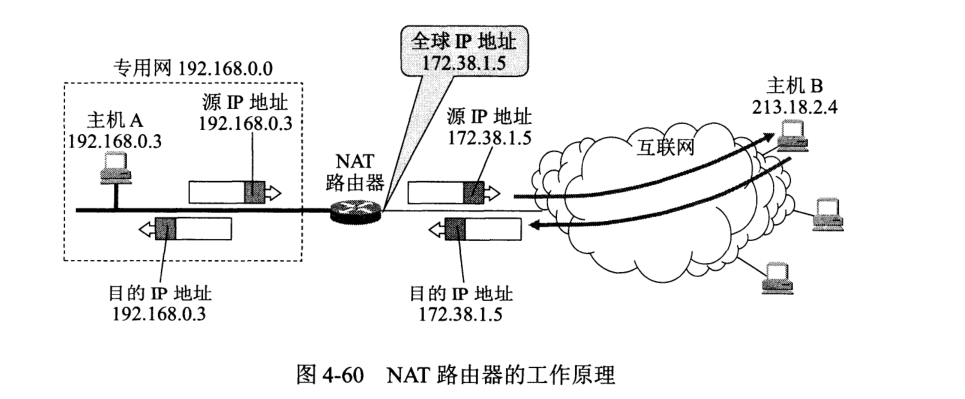
已经分配到本地 IP 地址,又想进行全球通信,则可使用 NAT。NAT 将每台计算机映射到 NAT 路由器的一个端口(每个端口具有一个全球 IP 地址),由此便可进行互联网通讯,此时目的主机只能知道 NAT 路由器端口的地址而不知发送端的地址。
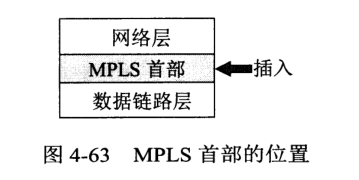
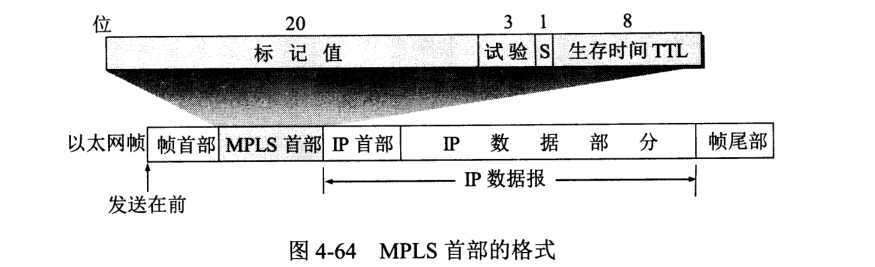
MLPS 作为一种 IP 增强技术,广泛应用在互联网中。特点如下:
在 MPLS 域入口处打上固定长的 MPLS 标记,然后对打上标记的 IP 数据报用硬件转发,只经过第二层,称为标记交换。
MPLS 域是指该域中有许多彼此相邻路由器,且均为支持 MPLS 技术的标记路由器 LSR。一个标记仅在两个 LSR 间才有意义。

如入接口 0 收到一个标记为 3 的 IP 数据报,路由器就知道应从出接口 1 转发且打上标记 1。
IP 数据报的集合,对路由器来说具有相同的性质,如下一跳,相同服务类别,同样丢弃优先级等。
例子:
链路是指从一个结点到相邻节点的一段物理线路(有限或无线),而中间没有其它交换结点。链路是一条路径的组成部分。
传输数据时,不仅需要物理线路,还需要一些必要的通信协议控制数据传输。若把实现该些协议的硬件与软件加到链路上,就构成了数据链路。现在最常用的方法是使用网络适配器(既有硬件也有软件)来实现这些协议。
早期数据通信协议曾叫做规程 (procedure)。因此在数据链路层,规程与协议是同义语。
数据链路层把网络层交下来的数据构成帧发送到链路上,以及把接收到的帧中的数据取出并上交给网络层。互联网中,网络层协议数据单元是 IP 数据报(或简称为数据报、分组或包)。
点对点信道通信时的主要步骤:
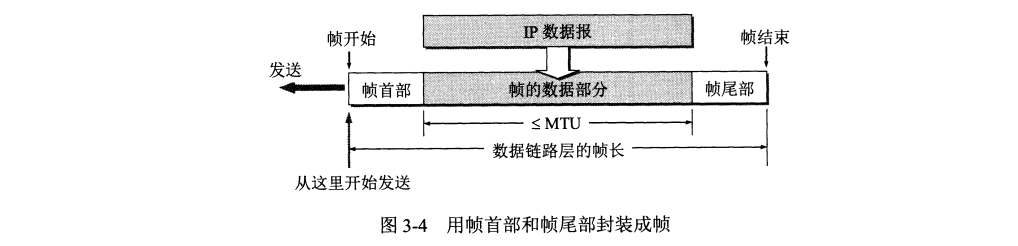
(1) 结点 A 的数据链路层把网络层叫下来的 IP 数据报添加首部和尾部封装成帧。
(2) 结点 A 把封装好的帧发送给结点 B 的数据链路层。
(3) 若结点 B 数据链路层收到的帧无差错,则提取 IP 数据报并交给网络层,否则弃帧。
三个基本问题:封装成帧、透明传输和差错检测。
封装成帧 (framing) 是指在一段数据前后分别添加首部和尾部,构成一个帧。首部和尾部的一个重要作用是进行帧界定。每一种链路协议都规定所能传送的帧的数据部分最大长度上限——最大传送单元 MTU (Maximum Transfer Unit)。
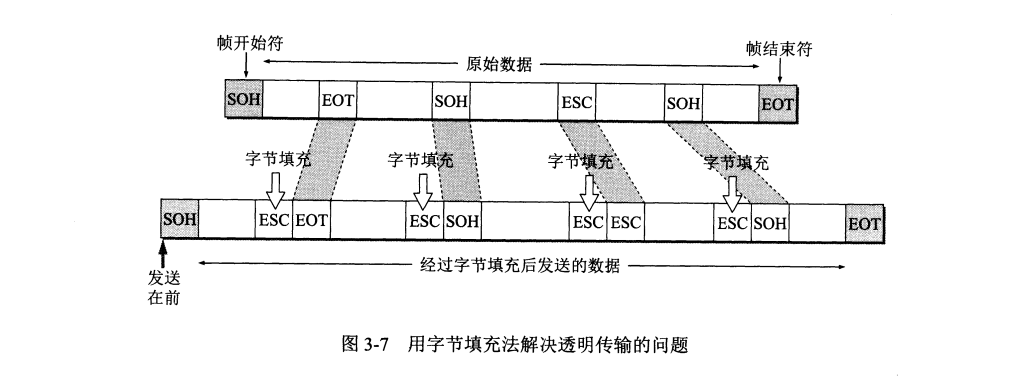
帧界定使用特殊的帧界定符,帧开始符 SOH (十六制编码 01)放于首部,帧结束符 EOT (十六进制编码 04)放于尾部。

当传输数据是非 ASCII 码的文件时,如果数据中某个字节二进制代码恰好和 SOH 和 EOT 这种控制字符一样,则会产生错误。透明传输的概念是指,无论怎样的数据通过,数据链路层都能原样无差错传输该数据。
为实现透明传输,发送端的数据链路层在发送数据中出现控制字符的位置前插入一个转义字符 ESC (十六进制编码 1B),接收端的数据链路层在将其送往网络层前提前删除这个插入的转义字符。此方法叫做字节填充或字符填充。
比特在传输过程中可能会产生差错,$0$ 变成 $1$,$1$ 变成 $0$,这种情况叫比特差错。同一时间传输错误的比特占总传输比特数的比率叫做误码率 BER (Bit Error Rate)。但实际数据传输误码率不可能降为零,因此位保证可靠传输,必须进行差错检测。目前广泛采用循环冗余检验 CRC (Cyclic Redundancy Check) 检错技术。

传输差错可分为两大类,一类是基本的比特差错,里另一类是更复杂些的帧丢失、帧重复或帧失序。因此出现比特差错与出现传输差错并不等价。为实现可靠传输,在 CRC 检错的基础上,增加了帧编号、确认和重传机制。现在互联网采用区别对待方法,对于通信质量良好的传输线路,不适用确认和重传机制,即要求数据链路层向上提供可靠传输;对于通信质量较差的链路,则采用确认重传机制,数据链路层向上提供可靠传输。
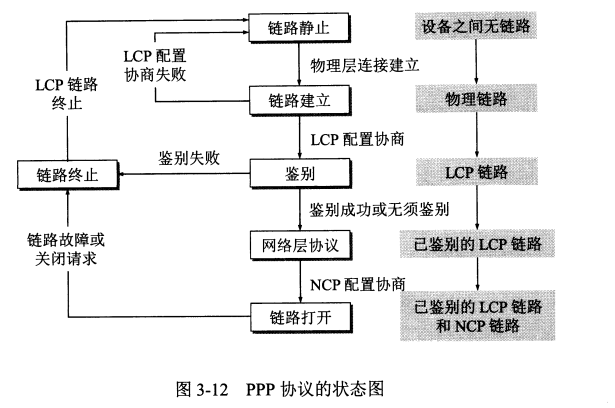
通信质量较差的年代,采用可靠传输协议是一种好办法,因此当时比较流行能实现可靠传输协议的高级数据链路控制 HDLC (High-level Data Link Control)。目前对于点对点的链路,则广泛采用简单得多的 点对点协议 PPP (Point-to-Point Protocol) 。
应满足需求:
PPP 协议的组成
(1) 一个将 IP 数据报封装到串行链路的方法。
(2) 一个用来建立、配置和测试数据链路连接的 链路控制协议 LCP (Link Control Protocol)。
(3) 一套网络控制协议 NCP (Network Control Protocol),其中每一个协议支持不同网络层协议。
首部第一字段和尾部第二字段为标志字段 F 。
首部第二、三字段无具体含义,未定义。
首部第四字段是 $2$ 字节的协议字段。协议字段为 $0x0021$ 时,PPP 帧的信息字段就是 IP 数据报;协议字段为 $0xC021$,则信息字段是 PPP 链路控制协议 LCP 的数据;而 $0x8021$ 表示这是网络层的控制数据。
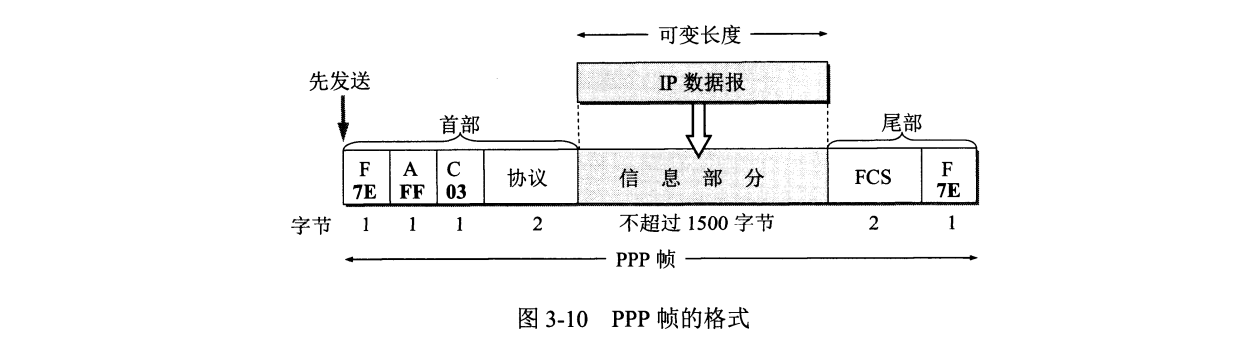

发送端每遇见 $5$ 个连续的 $1$ ,则插入一个 $0$;接收端采取相反操作。
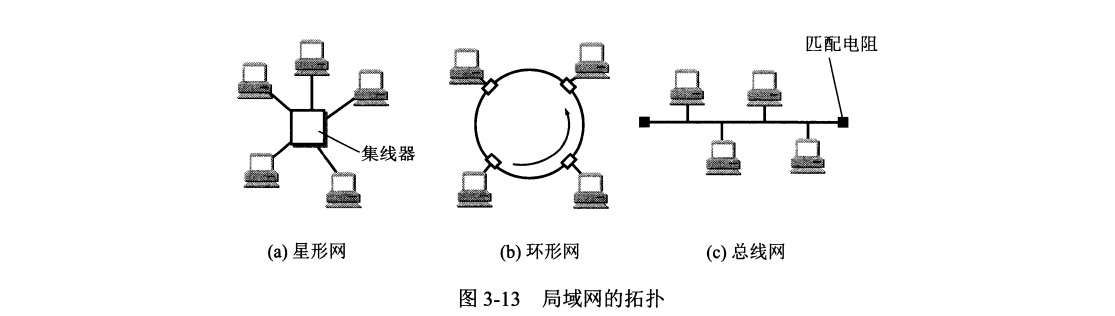
局域网最主要特点:网络为一个单位所有,且地理范围和站点数目均有限。
局域网优点:
(1) 可广播,一个站点可以很方便访问全网,主机可共享连接在局域网上的各种硬件和资源。
(2) 便于系统的扩展和演变,各设备位置可灵活调整或改变。
(3) 提高系统的可靠性 (reliability)、可用性 (availability) 和生存性 (survivability)。
局域网可按网络拓扑进行分类,分为星形网(核心设备集线器)、环形网、总线网几类,其中总线网以传统以太网最为著名。经过几十年发展,以太网已经在局域网市场中占据绝对优势,以太网几乎成为局域网同义词。
从 $10\ Mbit/s$ 到 $10\ Gbit/s$ 的局域网均可用双绞线。双绞线已成为局域网中的主流传输媒体。数据率很高时,往往需要使用光纤作为传输媒体。
共享信道在技术上有两种方法:
(1) 静态划分信道,如 2.4 中的频分复用、时分复用、波分复用和码分复用,但是这种划分代价较高,不适合局域网使用。
(2) 动态媒体接入,又称多点接入 (multiple access),特点是信道并非在用户通信时固定分配给用户。又分为两类:
现在用“传统以太网”表示最初流行的 $10 Mbit/s$ 的以太网。
世界上第一个局域网产品规约—— DIX Ethernet V2; 第一个 IEEE 的以太网标准 IEEE 802.3,数据率为 $10\ Mbit/s$。这两个标准区别很小,因此也常把 IEEE 802.3 局域网简称以太网。
为了使得数据链路层能更好适应多种局域网标准,IEEE 802 委员会将局域网的数据链路层拆成两个子层,即 逻辑链路控制 LLC (Logical Link Control) 子层和媒体接入控制 MAC (Medium Access Control) 子层。与接入媒体相关内容全部放在 MAC 子层,LLC 子层与传输媒体无关, MAC 子层对 LLC 子层来说是透明的。
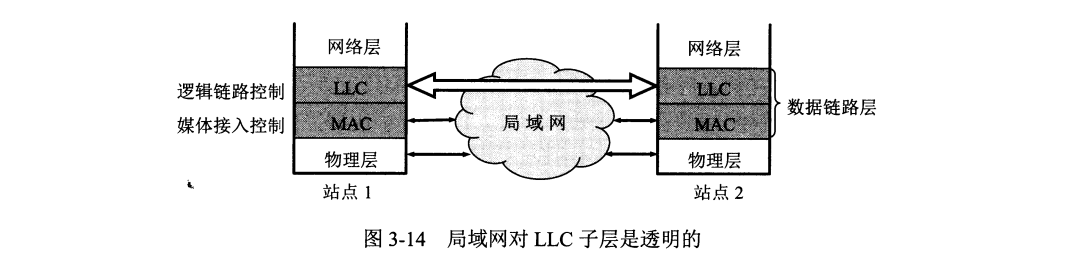
现代 TCP/IP 体系经常使用的局域网只剩下 DIX Ethernet V2 而非 IEEE 802.3 中的局域网,因此逻辑链路子层 LLC(即 IEEE 802.2 标准)作用已经消失,很多厂商生产适配器上仅有 MAC 协议而没有 LLC 协议。
适配器实现功能包含物理层和数据链路层两部分。
计算机与外界局域网的连接是通过适配器 (adapter)进行的。适配器本来是主机箱内插入的一块网络接口板,又称网络接口卡 NIC (Network Interface Card),或网卡。现在计算机主板上都已经嵌入该种适配器,不再使用单独的网卡,因此采用适配器这个术语更准确些。
适配器与局域网之间通过电缆或双绞线以串行传输方式进行通信,与主机则通过计算机主板上的 I/O 总线以并行传输进行通信,因此适配器一个重要功能是进行数据串行传输与并行传输的转换。
计算机的硬件地址在适配器的 ROM 中,而软件地址——IP 地址,则在计算机存储器中。
局域网上的计算机称为“主机”、“工作站”、“站点”或“站”。
为了通信减半,以太网采取以下两种措施:
第一,采用无连接工作方式,不必先建立连接即可发送数据。适配器对发送帧不进行编号,也不要求对方发回确认。因此以太网提供的服务随时尽最大努力的交付,即不可靠的交付。若目的站收到有差错帧,则丢,是否需要重传则有高层决定。
总线同一时间只允许一台计算机发送数据,否则会产生碰撞。以太网采用最简单的随机接入,但同时使用 CSMA/CD 协议处理碰撞,意思是载波监听多点接入/碰撞检测 (Carrier Sense Multiple Access with Collision Detection)。
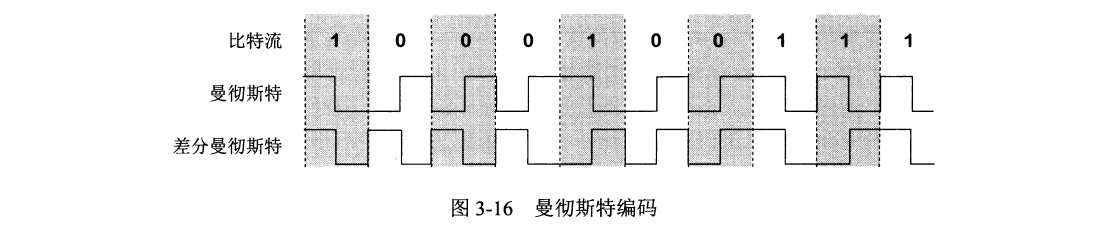
第二,以太网发送数据采用曼彻斯特 (Manchester) 编码的信号。优点是每个码元都出现一次电压变换,可以很方便地把位同步信号提取出来;缺点则是所占频带宽度比原始基带信号增加一倍。
介绍下 CSMA/CD 协议要点。
“多点接入”说明其是总线型网络。
“载波监听”是用电子技术检测总线上有无其它计算机在发送,其实就是检测信道。发送前和发送中都必须进行信道检测。发送前检测是为了获得发送权。发送中检测则是为了及时发现碰撞,即碰撞检测。
“碰撞检测“亦即“边发送边监听”,几个站同时在总线上发送数据时,总线上信号电压变化幅度会增大,超过一定阈值时,就视为产生了碰撞。一旦出现碰撞,适配器立即停止发送,等待一段随机时间后再次发送。
电磁波在 $1\ km$ 电缆的传播时延约为 $5\ \mu s$。把总线上的单程端到端传播时延记为$\tau$。最迟经过 $2\tau$ 的时延即可确认是否发生碰撞(信息来回一次最大可能时延)。
在使用 CSMA/CD 协议时,一个站不可能同时进行发送和接收,因此使用 CSMA/CD 协议的以太网只能进行半双工通信。
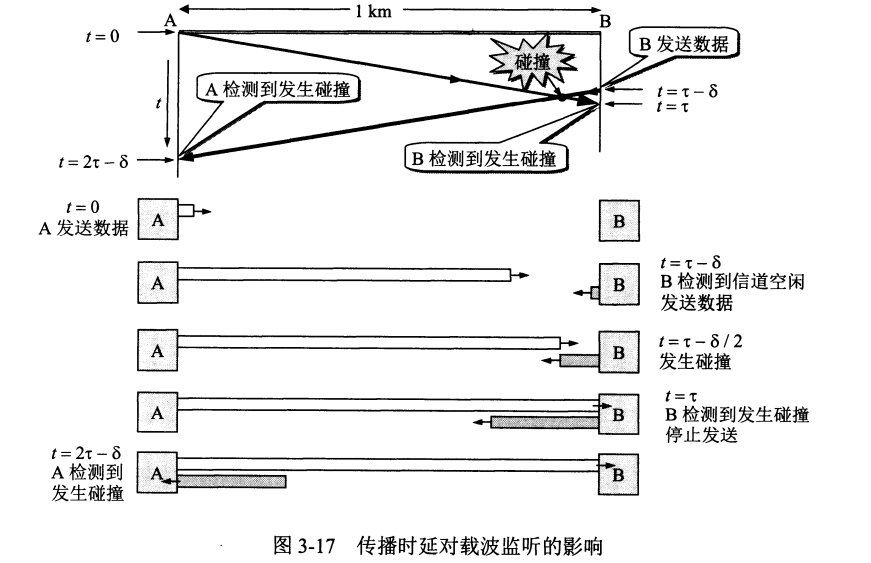
每一个站在发送数据后的一小段时间内,存在遭遇碰撞的可能性,这段时间是不确定的,因此称为以太网发送的不确定性。端到端往返时间 $2\tau$ 称为争用期。经过争用期检验后,才能肯定此次发送是否发生碰撞。
以太网使用截断二进制指数退避 (truncated binary exponential backoff) 算法确定碰撞后重传时机,这里不多赘述。
以太网规定一个最短帧长 64 字节,即 512 bit,这样发送一个帧的时间也至少需要一个争用期。凡是长度小于 64 字节的帧都是由于冲突而异常终止的无效帧。
强化碰撞是指发送数据一旦发生碰撞,除立即停止发送数据外,继续发送 32 或 48 比特的人为干扰信号 (jamming signal),以便让所有用户都知道发生碰撞。
以太网还规定帧间最小间隔为 $9.6\ \mu s$,相当于 96 比特时间,是为了使得刚刚受到数据帧的站的接收缓存来得及清理,做好接收下一帧的准备。
由此,CSMA/CD 协议总结如下:
(1) 准备发送:组装成帧
(2) 检测信道:检测到信道忙,则不停检测,直至信道空闲
(3) 发送:边发送边监听,发送成功则回到 (1) ;发生碰撞则执行指数退避算法,等待一定时间后回到 (2),若重传 16 次仍失败,则停止重传并向上报错。
集线器 (hub) 是一个物理层网络设备,通常与双绞线以太网相配合使用。10BASE-T 双绞线以太网的出现,是局域网发展史上一个非常重要的里程碑,从此以太网的拓扑就从总线型变为更加方便的星形网络,以太网也在局域网中占据统治地位。
集线器有如下特点:
堆叠式 (stackable) 集线器由 4~8 个集线器堆叠使用。
IEEE 802.3 标准还可以使用光纤作为传输媒体,主要作用于集线器之间的连接。
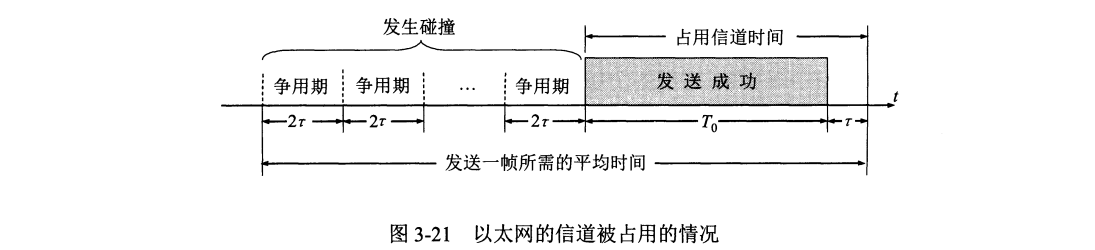
$a$ 趋近于 $0$,表示一发生碰撞即可检测出来,信道资源被浪费时间非常少。因此为了使 $a$ 值尽量小,以太网的长度受到限制($\tau$ 不能太大),同时以太网的帧长不能太短 (否则 $T_0$ 太小)。
理想状况下,不发生任何碰撞,则发送一帧时延为 $T_0+\tau$,而帧本身发送时延为 $T_0$,因此有极限信道利用率
因此只有当 $a$ 远小于 $1$ 时才能得到尽可能高的极限信道利用率。
局域网中,硬件地址又称物理地址或 MAC 地址(因地址用在 MAC 帧中)。
IEEE 802 标准为局域网规定一种 48 位的全球地址,是指局域网上每一台计算机中固化在适配器的 ROM 中的地址。
IEEE 的注册管理机构 RA (Registration Authority) 是局域网全球地址的法定管理机构,负责分配地址字段 6 字节中的前三字节(即最高 24 位)。世界上生产适配器的厂家都必须向 IEEE 购买由这三个字节构成的号,名称为 组织唯一标识符 OUI (Organizationally Unique Identifier),通常也称公司标识符 (company_id)。地址中后三个字节由厂家自行指派,称为扩展标识符 (extended identifier)。
IEEE 规定地址字段第一字节的最低位为 I/G 位。I/G 表示 Individual/Group。该位为 0 时,地址字段表示一个单个站地址。该位为 1 时表示组地址,用来进行多播。因此 IEEE 只分配前三字节中的 23 位。
第一字节低 2 位规定位 G/L 位,该位为 0 时是全球管理(保证全球没有相同地址),厂商向 IEEE 购买的 OUI 均属于全球管理。
适配器有过滤功能,适配器收下的帧包括以下三种:
(1) 单播 (unicast) 帧,收到的帧的 MAC 与本站硬件地址相同。
(2) 广播 (broadcast) 帧,发送给本局域网所有站点的帧(全 1 地址)。
(3) 多播 (multicast) 帧,发送给本局域网上一部分站点的帧。
所有适配器都应能够识别前两种帧,有的适配器可用编程方法识别第三种帧。
适配器还可设置为一种特殊的工作方式即混杂方式 (promiscuous mode)。窃听所有的帧,经常为黑客所使用。
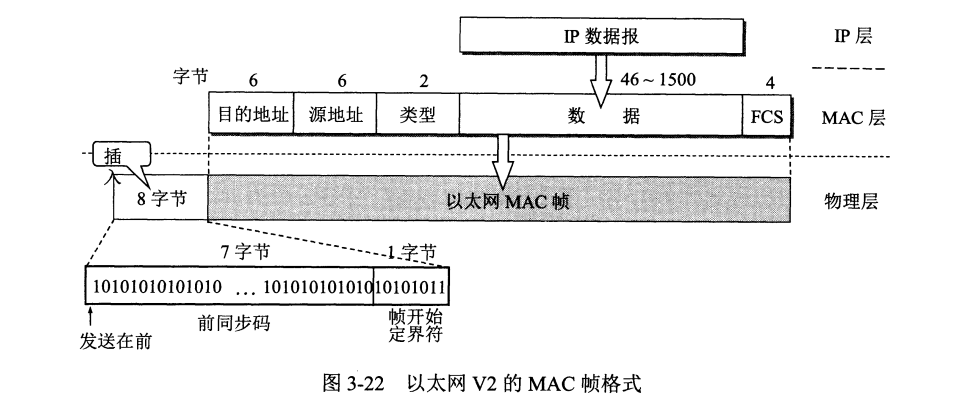
数据字段小于 64 字节时,MAC 子层会在其后加入一个填充字段。
MAC 子层向下传到物理层时还要在帧前插入 8 字段,第一字段为 7 个字节的前同步码 (1 和 0 的交替码),使得适配器接受 MAC 帧时迅速调整时钟频率。第二字段为帧开始定界符,定义为 10101011,前 6 位作用与前同步码相同,最后两个连续 1 预告信息接收。
由于曼彻斯特码的使用,以太网不需要着帧结束定界符,由此也不需要插入字节来保证传输透明。
扩展的以太网在网络层看来仍然是一个网络。
扩展主机与集线器之间距离一种简单方法是使用光纤和一对光纤调制解调器。
使用多个集线器,可以构成覆盖范围更大的多级星形结构以太网。
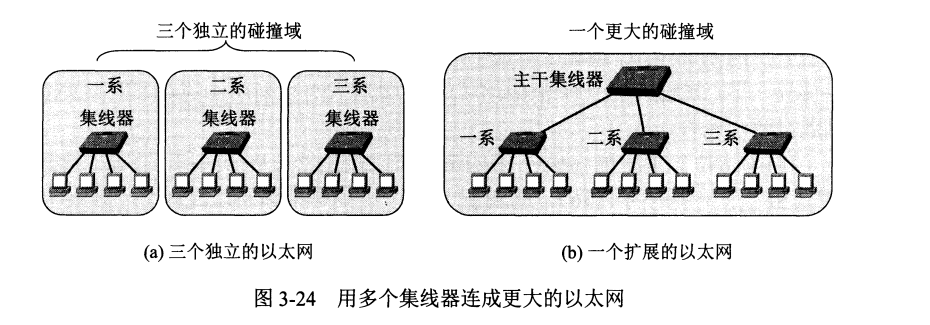
但这种多级结构的集线器以太网也有一些缺点。
(1) 多个系以太网相连把多个碰撞与变成一个,但此时最大吞吐量仍然是一个系的吞吐量 10 Mbits/s。
(2) 若不同系用不同以太网技术(如数据率不同),则无法互连。
最初使用网桥 (bridge),对 MAC 帧的目的地址进行 转发 和 过滤。
交换式集线器 (switching hub) 也称交换机 (switch) 或 第二层交换机 (L2 switch) 很快淘汰了网桥,这种设备工作在数据链路层。
实质上是一个多接口网桥,通常有十几个或更多接口。具有并行性,能同时连通多对主机进行通信,相互通信主机独占传输媒体,无碰撞地传输数据。
交换机的接口还有存储器,能在输出端口繁忙时将到来的帧进行缓存。
交换机即插即用,内部帧交换表是通过自学习算法自动逐渐建立。
许多交换机对收到的帧采用存储转发,但有些交换机用直通的交换方式,提高了帧的转发速度,但缺点是少了检查差错步骤。
懒得写,看书吧。
为防止环状网络拓扑导致的资源浪费,IEEE 的 802.1D 标准制定了生成树协议 STP (Spanning Tree Protocol),不改变物理上的网络拓扑,但从逻辑上切断某些链路,消除环状结构的存在。
随着站点数目增多和交换机成本的下降,传统总线以太网迅速为星形以太网所取代,但由于仍采用以太网的帧结构,故仍称以太网。
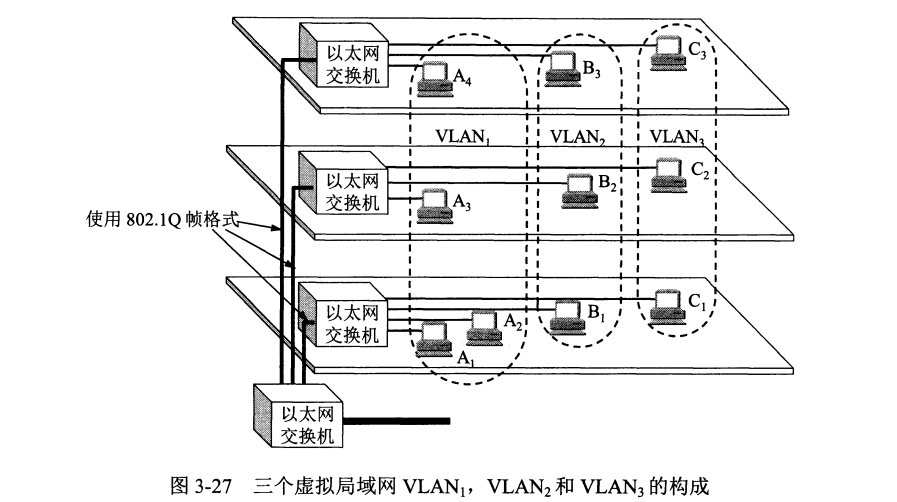
利用交换机能方便地实现虚拟局域网 VLAN (Virtual LAN) ,虚拟局域网限制接收广播信息的计算机数,使得网络不会因传播过多的广播信息(即“广播风暴”)而引起性能恶化。
1988 年 IEEE 批准了 802.3ac 标准,该标准定义了以太网帧格式的扩展,以支持虚拟局域网。
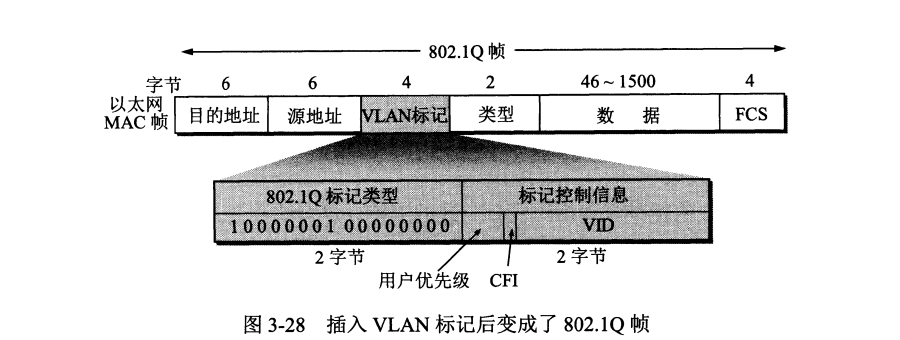
以太网最大帧长从原来的 1518 字节变为 1522 字节。
在双绞线上传输 100 Mbit/s 基带信号的星形拓扑以太网,但仍使用 IEEE 802.3 的 CSMA/CD 协议,又称快速以太网 (Fast Ethernet)。现在快速以太网正式标准为 IEEE 802.3u。
IEEE 802.3u 标准并未包括对同轴电缆支持,由细缆以太网升级到快速以太网必须重新布线,因此现在 10/100 Mbit/s 的以太网均无屏蔽双绞线布线。
更快的以太网就不写了,看书看吐了。。。。。#
本页面将计组和数据结构与算法两门课的编程作业代码于 ddl /发布三周后公布,仅供参考。如有错误或可改进之处,敬请联系 Lg,直接 qq 联系或 1370120724@qq.com 均可。
也许你感觉自己的努力总是徒劳无功,但不必怀疑,你每天都离顶点更进一步。今天的你离顶点还遥遥无期。但你通过今天的努力,积蓄了明天勇攀高峰的力量。